![Cover image for [Feedback] GCP : Cross region Data transfer with BigQuery. Part 2 - Schema drift with the Google Analytics use case](https://media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fpvcrxnj4jw1r3i6lm1n2.jpg)
In a previous article, we detailed the process that we set up to transfer data incrementally and periodically between GCP regions in BigQuery. It’s a common problem when working in a global context where your data resides in locations all over the world. If you missed it, be sure to catch up here : [Feedback] GCP : Cross region Data transfer with BigQuery. Part 1 - Workflows and DTS at the rescue
Now that you have the architecture in mind, let's dive into a problem we had when working with Google Analytics (GA) : the schema drift situation.
The use case : Google Analytics
Let's add some context : the company I am working for owns websites. A lot of them. And like pretty much everybody they use Google Analytics to track the audience, user behavior, acquisition, conversion and a bunch of other metrics.
Additionally, they use this GA feature that lets them automatically export the full content of Google Analytics data in BigQuery. Each website -or view in GA jargon-, is exported in a dedicated dataset (represented by the viewId) and a table (a shard) is created each day with the data from the day before. Same as before, the data is split in different projects, located in remote GCP regions according to the country of management of the website.
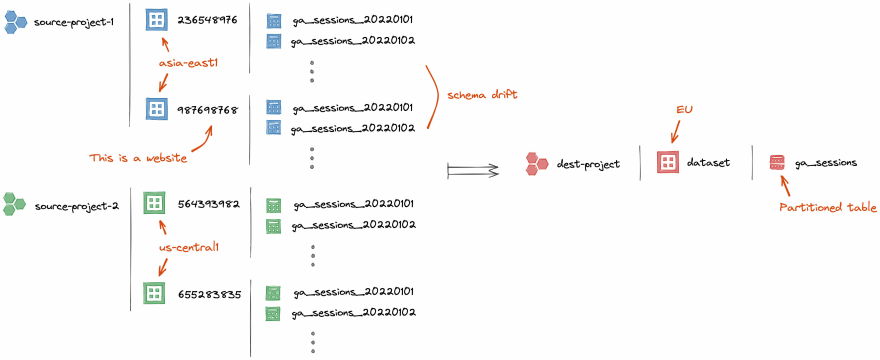
The problem is the configuration to export data into BigQuery is done and maintained manually for each website ! Moreover from time to time new websites are created and some of them stop publishing data (because they were closed for instance). And Google Analytics, like every information system platform, is constantly evolving : adding dimensions, features and metrics (and so columns in the data model), but the system does not update the schema from all the previous tables already created and it leads to a large issue : the schema drift.
What we needed to do
The very big workflow that we made to transfer data cross region, takes as argument a SQL query to read data from the source. But here, compared to the situation described in the previous blog post, the shared tables are located across many datasets (see schema above). Our first reflex was to pass as input query something like this :
SELECT * FROM `source-project-1.236548976.ga_sessions_*`
UNION ALL
SELECT * FROM `source-project-1.987698768.ga_sessions_*`
UNION ALL ...
-- For each dataset in a given project
But this was the beginning of our misery : the schema from tables in dataset 236548976 and 987698768 is not exactly the same (probably one of them was initiated later, with some changed fields). Easy, you would say : just specify the explicit list of fields in the SELECT statement, replacing missing fields with something like NULL as <alias>. Well, it’s not so simple, because :
The schema from the Google Analytics data model is One Big Table with over 320 columns, distributed on a 4 level depth of nested columns, repeated fields, array of repeated fields, etc... the differences could be at any level, and different from a dataset to another.
We have hundreds of website, and so hundreds of datasets
A new dataset can be added at any time and the solution had to automatically load the new data without further re-configuration.
We needed a way to automate all of this mess.
The first idea: a magical stored procedure 🧙🏼♂️
The first, and I think the more logical, reflex that we had was to generate SQL queries. And what a nicer way of doing this than by using SQL ? Given a projectId and a dataset, the procedure would have to generate something like that :
SELECT
channelGrouping AS channelGrouping,
clientId AS clientId,
STRUCT(
device.browser AS browser,
-- this field does not exist in the current dataset
CAST(NULL as STRING) AS browserSize,
...
) as device,
...
ARRAY(
SELECT
STRUCT(ARRAY(SELECT STRUCT(...) as promotion FROM UNNEST(product)) as product)
FROM UNNEST(hits)
) as hits, ...
FROM `source-project-1.236548976.ga_sessions_*`
With, let's remind it, a 4 level depth of nested structures and more than 320 columns. Fortunately, like most respectable databases, BigQuery has an internal hidden table called INFORMATION_SCHEMA with all the metadata that we needed.
Not without some effort, it worked : with a recursive and generic approach, we succeeded in dynamically generating the massive SQL query. We only needed to call the procedure for each dataset to have the SELECT statement and perform an UNION ALL, and the problem of schema drift would have been solved !
But this was not the good approach : we had fun building the magical stored procedure but it was too slow, consuming too many resources, and the generated query was so large (when joined together with UNION ALL), that the content didn’t fit in a variable in our orchestrator 🤦♂️.
The real magic resides in simplicity
Most of the time, the simpler the better. We actually realized quickly that BigQuery already had its own way of dealing with the schema drift problem : it’s the wildcard functionality and we were using it all along !
On a sharded table structure, a table is actually splitted in many smaller tables with a suffix to differentiate them (most commonly a date). Conveniently, BigQuery let you query for all the tables sharing the same base name with the wildcard annotation, just like we did to have all the data from a website :
SELECT * FROM `ga_sessions_*` process all the data from tables that match the pattern ga_sessions_*. And this works even if the schema has evolved since the first table !
BigQuery automatically applies the schema from the last created table to the query result and completes the missing fields with NULL values. Sadly, doing the same from a batch of dataset if not possible (like `project.*.ga_sessions_*` so we got around the issue by doing the following:
For each dataset in the source, create a large table that contains all the data from the
ga_sessions_*sharded table. This table is named with the datasetId as a suffix, in a buffer project, dedicated to the replication purpose. In practice this table contains all the partitions created since the last transfer (so most of the time 1 partition, except in the init phase)Create a "fake" empty table with the exact same schema as the destination table. This schema is our reference, where the other tables might differ slightly. (it’s the
ga_sessions_DONOTUSEtable in the schema bellow)Use the wildcard syntax again to append all the data into the final table (partionned) : the suffix is not a date anymore but the source datasetId ! As the fake DONOTUSE table is always the last created, it’s schema is applied to all the other tables.

Now, next time Google updates the GA data model, we only have to impact the change in our final partitioned table and the whole process will adapt and won’t fail, even if the new columns are not yet present in every source table at the same time. On the downsides, with this process we might miss schema update from the source if we aren't aware of new columns, but for now the current architecture fits our need.
Conclusion
To be honest I felt a bit ashamed to not have thought of the second solution sooner, it is so simple and much more maintainable than the first one ! It works like a charm in production today and we are transferring daily, tens of gigabytes of data, coming from thousands of websites across all the regions of GCP to a unique, massive partitioned table that is available to Analysts.





Top comments (0)