
English version / Version Française ici
Forecasts on dev evolution, based on TRIZ
The TRIZ laws of technical systems evolution show that development will become simpler and tend towards an ideal. Inspired by this method of innovation, I believe that this simplification will be done in 2 main ways, declined in 5 trends.
Simplification by reducing errors
ergonomic visualization
abstraction
Simplification by reducing tasks
unification
automation
delegation
I propose to detail these 5 trends and see how they allow us to foresee dev evolution. As an example, I will then forecast the evolution of unit tests.
Ergonomic visualization
Ergonomic visualization = user-friendlyness
Linux is free, open-source, fast, and secure compared to Windows or OSX which yet are much more popular for regular users.
This is no coincidence. Windows and OSX are much more visually ergonomic, more user-friendly, and more compatible than Linux, whether used as a command line or as a GUI. Their well-thought-out graphical user interface simply makes them simpler to use, which is a real asset for a tech to be adopted, especially for regular users.
On the other hand, CLI requires most of the time a learning process, and/or a reference document, and is not intuitive. Yes, it is useful in some cases, even unavoidable for some operations that are much faster to do with a good command line than with UI. But I'm convinced that too often, CLI is not the right choice, and is a feature implementation that didn't go all the way: it lacks a graphical layer.
Ergonomic visualization = less errors
Furthermore, a graphical user interface avoids errors that could be made via code or via a command line. This is due to the fact UI can easily constrain the possible actions or options. This is seen, for example, in No or LowCode apps. In bubble.io, if we assign an action to a button, it looks like this:
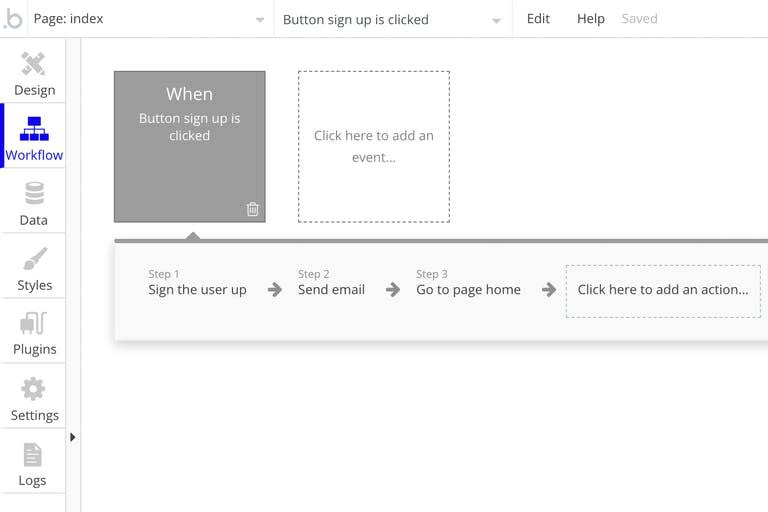
There is a drop-down list that allows you to choose the type of event to detect (click), and several others that allow you to choose the actions to be performed (identify, send an e-mail, redirect to reception). Not only is it intuitive, but these drop-down lists, unlike code or commands, prevent syntax errors, as well as calling inappropriate functions, or passing inconsistent params.
Ergonomic visualization = time saving
User-friendly interfaces also save time. They can even save time for devs, even though they could do without UI because they have the ability to learn CLI or languages.
Because that's not the point: we are here trying to find out what is the most efficient way to master an API starting from 0. If you are a shell master frameork CLI master, then I have no doubt you can do things quickly.
But you had to learn these commands, which represents a significant cost in terms of time. And when we talk about Code Ergonomics, we are trying to reduce this cost. It turns out an unknown API is much faster to master when it is visual than when it is operable by code or by a CLI.
Let's take the example of setting up a dev environment. Currently, you can use a first command line to clone a git project, or to start creating a starter project. Then you need to run another command to start importing modules. Then another one to serve the project, with in the meantime a possible modification of webpack or other bundler config to fit our requirements in terms of transpilation, linting, hot-reloading, etc... In codesandbox.io, all this is visual, and requires 3 clicks. Simply put, we save time.

Is it devs job to make efficient UIs?
It's not ideal, but when working on a solo project or in a small team that doesn't have a graphic designer or UX expert, devs have to design well thought-out interfaces.
All too often, however, they tend to neglect UI ergonomics, considering that it is not their responsibility and that their added value lies in the implementation of functionalities. There is an "inappropriate partition" between engineering and graphic design.
However, in the Renaissance, there was no partition between Science or Art. People tried to be complete, to master both. So I think devs would benefit from trying to create efficient and well thought Uis.

Abstraction
Using a high-level language, and separating app description from its engine, allows us to benefit from the permanent evolution of patterns and syntaxes without having to train continuously: because apps remain optimized without having to be rewritten. This matter needs its own article which you can find here.
Unification
In TRIZ's laws of technical systems evolution, there are multiple trends. One of them concerns the merging of system components. Please refer to the "Using dissimilar Elements" or "Using Similar Elements" trends in this graph.
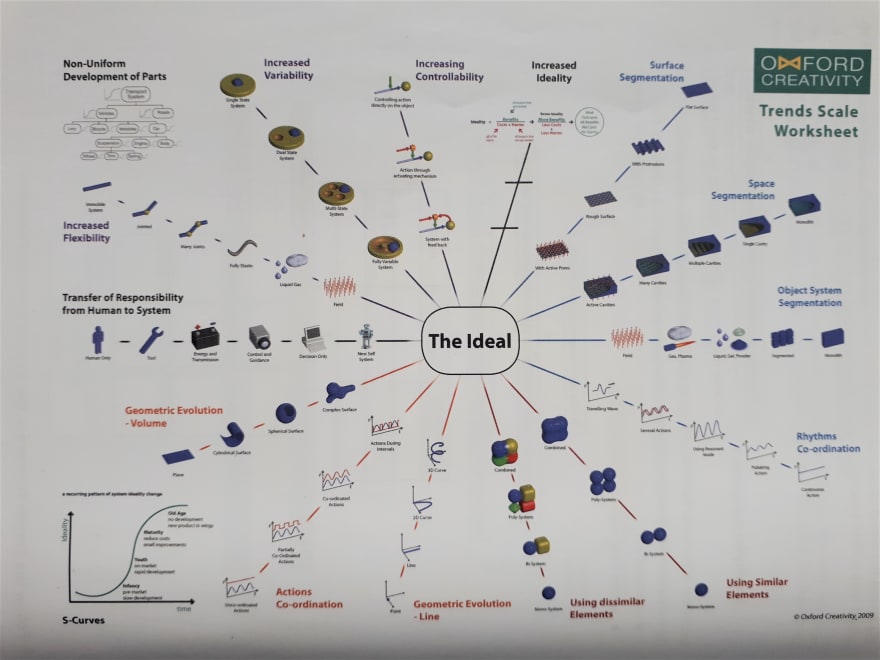
The many dev tools will unify to become an all-in-one programming environment, kind of like Flash years ago (although server-side was missing), Meteor, Unreal Engine, or Unity.
This will merge the multiple tools that are currently used separately: bundler, module manager, versioning, transpiler, CLI, etc. Everything will be integrated into the code editor, most often in the form of options, parameters and menus.
Again, we can already see it in codesandbox.io as well as in visual studio code which integrates a terminal, a debug console, and all kinds of modules.

The 6th TRIZ law of evolution - Transition to the supersystem, also specifies that a system will become part of its supersystem, i.e. its environment.
So the programming environment (system) will be integrated into the cloud (super-system). There will no longer be any local / remote separation. Everything will be online.
We already can see it with CodeSpaces from GitHub (still in beta version) which is a cloud IDE:

Automation
This is probably the most important point. Thanks to automation, most configs can be avoided.
No more env. config
Like codesandbox or thanks to the tree-shaking of parceljs, dev environments will be able to self-configure by analyzing projects source code and the dependencies.
No more versioning commands
Using the command line can be improved. Backups can be partially automated, similar to the incremental backups in Synology Cloud Backup or Apple's TimeMachine :
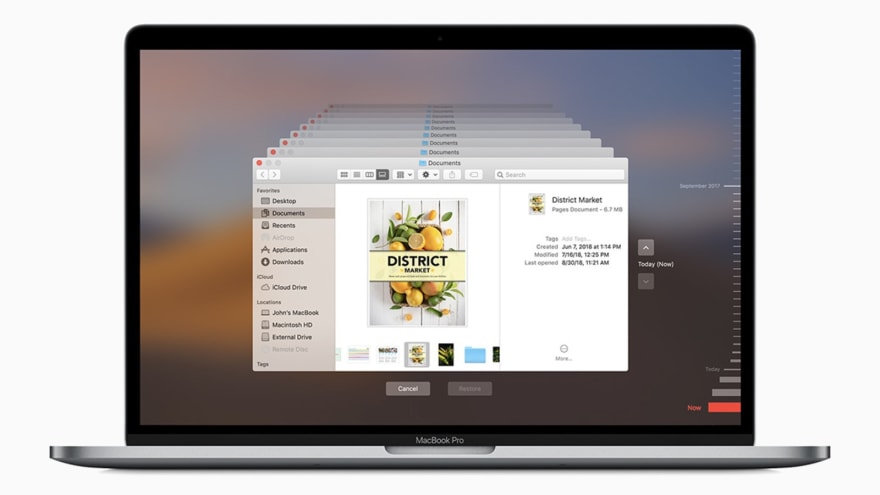
On a side note, I'd like to specify that visually, versioning could be inspired by Wordpress or Adobe Suite's history managers, but with the added capabilities of forking, merging and other subtleties of git. There is a lot of room for improvement, but in the meantime, tools such as Git Kraken or Git Tower offer somewhat improved UIs.

No more cloud configuration or tedious deployments
Like softaculous, which allows to set up or clone a Wordpress or other system project in one click, clouds could be automated.

**WebHosts could technically detect app boilerplates and config files, deduce all dependencies, auto-load them and set them up. **After all, we mentioned Parcel is already able to do this for dev environments.
In addition, easy deployment could be done via a single Deploy button in the IDE. Like in Codespaces.
Cloud services still have a lot of room for evolution, as they didn't adapt well to the new practices of front-end development. They should be automated, as this would provide a real service to developers, who are their typical users and customers. They would thus considerably improve their market share.
No more unit tests programming
Beyond the debate on the usefulness of unit testing, which we didn't have to deal with for decades while many applications were still of high-quality (thanks to user testing), we are still too low-level when we code them.
These tests could be partially automated as well. I will discuss this case in more detail in the last part of this article.
But above all: less, or not at all, code.
Apps could be described either through a high-level language or visually. Then this description could be translated by an interpretation engine.
Here we can also refer to No or Low-code platforms. The best example in my opinion is still bubble.io which is very flexible and not only limited to the creation of showcase websites as many might think. I invite you to try their 5min tutorials to get an idea of its flexibility.
This Description / Engine separation is the prerequisite for efficient automation. It can be found, for example, in DBMS, with SQL that can be combined with the MyISAM or InnoDB engines.
There is much to be said on this matter, which I approach along with Abstraction, in this article.
Delegation
Currently devs are taking care of almost everything: architecture, environment configuration, development, testing, debugging, versioning, server configuration, and online releases. How can they master everything? Is it possible to become a specialist in all those matters? Do we accept not to be specialized in anything? Or can we make changes to optimize this situation?
Devs tasks will be reduced: what can't be automated will be simplified. What can't be simplified will be left to specialists.
I'm particularly thinking about cloud management, which I mentioned earlier: if a webhost offers a real one-click deployment, adapted to the most common project architectures and framework, he will win a lot of market share.
Last but not least, within the dev. community itself, I think that a distinction between devs who make apps vs devs who make devtools will be necessary, in order for them to specialize and learn what is actually useful regarding their needs. I'd like to avoid repeating myself, so I invite you to read this article for more details.
Example: unit testing evolution
Let's try to see through this example how these 5 trends allow us to imagine the evolution of unit testing.
The problem
In addition to being boring, writing unit tests roughly doubles the time and therefore the cost of development.
Possibilities of evolution, based on the 5 principles
Tests would be integrated into the IDE, which would be able to self-test a project (unification of components and delegation of tests to the IDE) by pressing a button rather than by a CLI (abstraction, visualization).
The IDE would automatically test (automation), for each UI component, all possible events (a button would be clicked, double-clicked, hovered, while a form would be sent, reset, etc.). The reactions to those events would be analyzed and this would highlight any inconsistencies or conflicts in the application.
For example, the IDE might show that the same function is invoked several times but with arguments of different types, or that its return values are of different types.
The result would then be a list of these inconsistencies, display in an interface (visualization), which would ask us to decide on the input/output really expected. This would be similar to GitKraken when it asks us to decide on a merge conflict, but here, the choice would most often be made though simple drop-down lists.
Conflict resolution would thus automatically apply changes to the tests description files we currently create by hand.
Thank you for reading me this far.

Top comments (0)