It may happen that you are interested in executing a batch of SQL commands whose results produce not only one resultset, but more than one. This helps to avoid doing additional roundtrips to the database. For example you can return suppliers and customers at once executing the following statement in the same command:
SELECT … FROM dbo.Suppliers;
SELECT … FROM dbo.Customers;
I’m not really fond of this approach, and if the two objects are independent from each other (like in the sample) I would rather prefer two separate asynchronous (parallel would even be better) calls to the database, but you don’t always have this option, or maybe you’re in a case where a plain and simple approach is preferred.
In any case, if you have multiple resultset, Dapper can help you, via the QueryMultiple method:
var results = conn.QueryMultiple(@"
SELECT Id, FirstName, LastName FROM dbo.Users;
SELECT Id, CompanyName FROM dbo.Companies
");
var users = results.Read<User>();
var companies = results.Read<Company>();
QueryMultiple returns a GridReader object that allows you to access the available resultset in sequence, from the first to the last. All you have to do is call the Read method, as shown in the above code, to access each results. Read behave exactly like the Query method we already discussed in the first article. In fact it supports all the specialized method that also Query supports
ReadFirstReadFirstOrDefaultReadSingleReadSingleOrDefault
all the Read methods can also be called asynchronously via ReadAsync.
A typical Use Case
So, even if not so common, a use case for such method exits, and is related to the necessity to create complex object with data coming from different tables.
Let’s go with another typical example here: Customers and Orders. You want to load a customer object with all related orders.
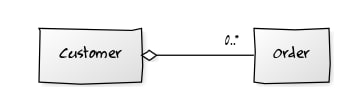
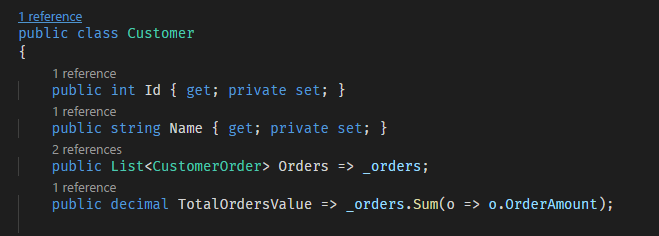
As one can guess, the Customer object has a list of Orders:
If you’re a database guy you probably immediately thought to solve the problem by joining Customers and Orders table

which will produce the following result:

Unfortunately there are a few problems with this approach from a developer perspective, even if the correct one from a database perspective.
The first problem is that we had to create column name alias, since both the tables have the Id column. By default Dapper maps columns to properties by name matching, and thus the introduced alias will prevent this native behavior to work properly. As we’ll see in a future article, we can handle this case, but it will make our code a little bit more complex. And I don’t like making the code complex of such small thing: introducing complexity when it is not really needed is always a bad idea.
The second problem is that the resultset have has many rows as many orders the customer placed. This in turn means that customer data (Id and Name in the example) is returned for each order. Now, beside the fact that this will waste bandwidth, impacting on overall performance and resource usage, we also have to make sure that we actually create just one Customer object. Dapper won’t do that for us, so, again, additional complexity needs to be introduced.
As you can understand, the two aforementioned problems prevent the usage of the SELECT…JOIN approach with Dapper. The correct solution is to query the Customer table and create the single Customer object and then query the Order table, create the Order objects and the link them to the created customer.
To avoid doing two roundtrips to the database to get customer and orders data separately, the multiple resultset feature can be used:
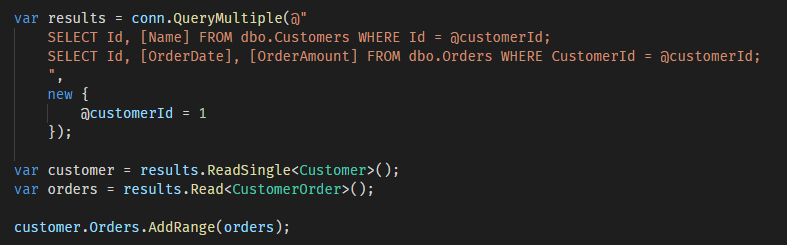
Of course in case you’re dealing with multiple commands like above you may also want to make sure you wrap everything in a transaction, to assure data consistency. Transaction support will be discussed in a future post but in case you want to go forward, know that Dapper supports transaction via the TransactionScope option.
Samples
As usual an example that shows how to use the discussed feature is available here:
Conclusions
The described feature helps to solve a very specific problem, keeping the performance high and the code clean, but has a big limitation: what if, in addition to the Order we also decided to get the Order Items? The discussed feature wouldn’t have helped and we would had to do a separate query to the database, for each order, to get the related items. Really not good for performance. Luckily if your database supports JSON, (SQL Server 2016 and after and Azure SQL both supports it) there are a much better and powerful way to elegantly solve the problem of mapping rows to complex objects. We’ll discuss it very soon.
What’s next
Next article will be dedicated to a feature somehow related with what discussed here: “Multiple Mapping” or automatically mapping a single row to multiple objects.





Top comments (4)
Hi , few questions. Is
Dapper.NETbetter and fast thanEntityframework Core? Can we call a Stored Procedure in Dapper.NET ?Hi Dapper is surely faster (you can check the performances here: github.com/StackExchange/Dapper#pe...) but is not necessarely better than EF Core. EF Core is a full fledged ORM, with a tons of features that Dapper doesn't have. On the other hand if prefer direct control on what SQL code is executed, Dapper is a great micro-ORM that doesn't add almost any overhead and thus is really fast. It just removes the plumbing code. Sure, you can use Stored Procedure with Dapper. If you just want to call Stored Procedures, I would definitely choose Dapper. In the first article of the series (dev.to/yorek/get-started-with-dapp...), there is a section on Stored Procedures and Parameters. Give it a read to have the complete picture.
Thanks, What are the reasons to prefer
Dapper.NEToverADO.NET? I think ADO.NET should be more faster thanDapper.NETand Entity Framework.Also I don't like to see SQL select statements inside Application code. So I create ADO.NET repository with Stored Procedures for SELECT. I think it's more clean and maintainable.
Dapper.NET extends ADO.NET. Great, you're following the best practices already, by separating SQL code from .NET code and using Stored Procedures.