
In the previous episode we introduced a simple but effective model to characterize the performance of a single actor:
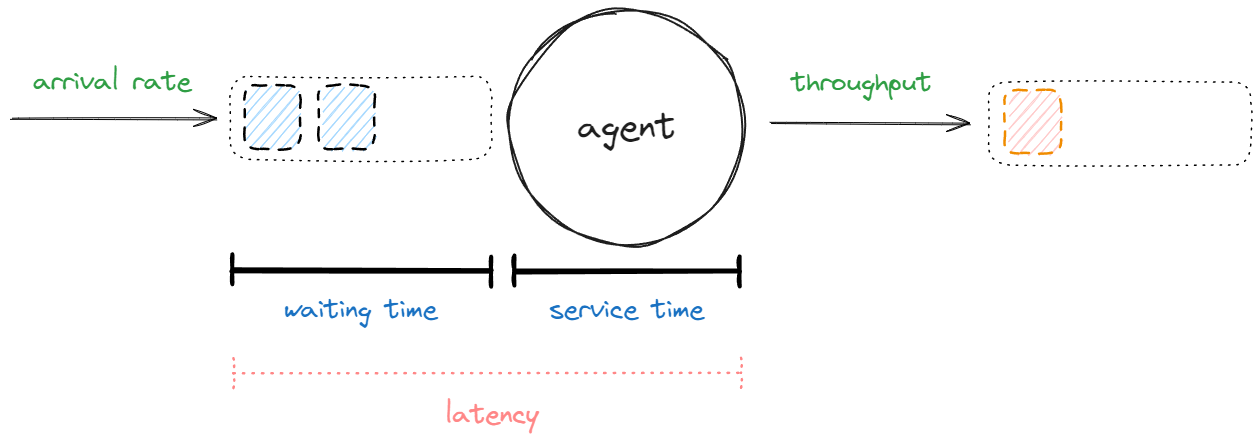
In particular, we explored throughput as a key indicator and we discussed that it’s influenced by the other factors:
- arrival rate: how fast messages to process arrive;
- waiting time: how fast messages in the queue are handed over to the agent;
- service time: how fast messages are processed by the agent.
We also mentioned that latency is the sum of waiting time and service time.
In essence, to increase throughput, we can adjust these parameters or try scaling the system by distributing work across multiple agents (or threads).
Throughput can be monitored over time, as demonstrated with fps_estimator, and benchmarked in isolated tests, as demonstrated with frequency_calculator. When this indicator becomes a concern, gathering additional information about the system becomes important. Firstly, it’s worth thinking of which entities come into play in SObjectizer to influence the above-mentioned parameters:
- arrival rate is actually determined by the system (meaning, for example, by the requirements of the problem to solve or by the data sources – e.g. the camera) and might be influenced by facilities executed at the sender site such as filters (as mentioned in a previous post, slow filters cause slow sending, possibly resulting in a worse arrival rate);
- service time is defined by the agent but it can be indirectly influenced by other factors (e.g. CPU contention might have an impact, as seen in the previous post);
- waiting time is mostly determined by the dispatcher, which is responsible for dequeuing a message and executing an agent’s handler for that on a specific thread. However, it’s evident that waiting time may also be indirectly influenced by service time because messages, unless processed by thread-safe handlers, will be handled sequentially by an agent. The longer the service time, the longer the wait to handle the next message.
Moreover, there are scenarios where we can actually distribute work across multiple workers. In this context, when there is an observed increase in overall throughput, it is likely due to a reduction in waiting time rather than service time (which may even be prolonged when the contention of the CPU is significant). Put simply, the time required to dequeue N messages will decrease but time to handle one will not. In this case, it’s common to say that the latency decreased (as we have seen, throughput and latency go together).
When increasing throughput by distributing work is not feasible, we typically turn our attention to waiting time and service time. However, since waiting time is not likely under our control, it is more useful and simple to initially gain an understanding of service time.
The most favorable situation to measure service time is when the logic is outside the agent. While this may seem like an obvious observation, there are scenarios where we begin with legacy code and migrate certain parts to agents, or we utilize functions and classes that already exist outside agents and have been tested in isolation already. For instance, in the case of the face_detector, since the face recognition routine is quite standard, the core logic could possibly be outside the agent. In this case, to measure the service time we would simply measure the performance of that function.
However, this is not really the case for agents such as image_resizer and face_detector as the logic is totally inside such agents. After all, the actor model is conceived to encapsulate logic within agents and refer threading and messaging to the framework. What to do in this case?
In this article, we will explore a technique to measure the service time of agents in isolation. This approach should be used in tests only and it’s different from another “monitoring” tool provided by SObjectizer that will be discussed in a future post.
Where the measure should be placed
As said, service time is the measure of the agent’s reaction to a specific message, without considering waiting time. For example, measuring service time of image_resizer, ideally would be equivalent to this:
so_subscribe(m_input).event([this](const cv::Mat& image) {
auto tic = steady_clock::now();
cv::Mat resized;
resize(image, resized, {}, m_factor, m_factor);
so_5::send<cv::Mat>(m_output, std::move(resized));
const auto service_time = std::chrono::duration<double>(toc - tic).count();
});
This measurement might be taken multiple times, and the average used as a reference.
A non-intrusive approach to extract this metric requires us to enter a bit more into some internals of SObjectizer. We know that the entity responsible for executing an agent’s message handler on a viable worker thread is the dispatcher. A dispatcher also manages message queues for agents that are bound to it. This is an important distinction of SObjectizer from other actor frameworks: a message queue does not belong to an agent; rather, it is created and managed by a dispatcher. Another differentiating factor of SObjectizer from other actor frameworks is the number of message queues. In the “classical” actor-based approach, each actor has its own queue for processing messages. In SObjectizer, a dispatcher chooses how many queues are required to serve agents bound to that dispatcher. It’s an implementation detail.
In other words, a dispatcher is responsible for:
- creation and deletion of worker threads;
- creation and deletion of message queues;
- extraction of messages from queues and invocation of message handlers in the context of dispatcher’s working threads.
The last point hints that dispatchers might be the entity where we can place code time message handlers execution. Is that correct?
Commonly speaking, yes. Formally, we need to grasp a few more details.
After an agent is created, it is bound to a message queue. This fact determines the actual start of its work. Messages directed to the agent are pushed to that queue and eventually extracted to be handled on a certain thread. As we have learnt, this is the dispatcher’s job. How is the dispatcher bound to the agent? In the series, we mentioned the “dispatcher binder” is responsible for this purpose. For example:
env.introduce_coop(so_5::disp::active_obj::make_dispatcher(env).binder(), [](so_5::coop_t& c) {
// ...
});
The one million question is: does make_dispatcher return a concrete class implementing a sort of “dispatcher interface”? Somehow. It returns a dispatcher_handle_t that is just a wrapper around a dispatcher binder. The dispatcher binder provides such an interface, in particular it exposes a function that binds an agent to a message queue (formally, an “event” queue) that provides an interface for “pushing a message”. Thus, strictly speaking there is no “dispatcher” interface to implement. Instead, there are two interfaces that are commonly implemented to create a custom dispatcher:
- dispatcher binder (
disp_binder_t) - event queue (
event_queue_t)
The dispatcher binder serves as the interface that allows binding an agent to a customized event queue. The event queue, in turn, is the interface that describes how events are stored for handling. In the SObjectizer slang, the term “dispatcher” commonly refers to the bunch of implementation details that connect these elements behind the scenes. It’s the strategy responsible for dequeuing events from the queue and enabling their execution on a certain thread. Practically speaking, this usually requires us to develop both a custom dispatcher binder and a custom event queue. Things will be clearer once we get to the implementation.
The good news is that the complete code for our “dispatcher” is quite short and can serve as a starting point in case you want to roll your own dispatcher. There are a few new concepts of SObjectizer we’ll meet and discuss along the way.
Service time estimator dispatcher
Our attention needs to be directed towards the purpose of this “service time estimator dispatcher”. The objective is to isolate the portion of code where an agent’s handler is invoked and measure the time taken for that invocation. Possibly, we set the number of expected messages and calculate the average service time taken to process them all. We can ignore any thread_safe marker. Also, as the dispatcher should be used in isolated tests only, we can assume it will be bound to a single agent only.
The approach will be simple and self-contained: we launch a single worker thread that dequeues and invokes all the events one by one. Since we do have control, we time the code portion that invokes the handler.
There are a few details we need to decide:
- where to store events?
- should we distinguish start/finish events from others?
- how to manage the worker thread?
The responses to these questions may differ, but we can adhere to straightforward yet impactful decisions:
- we use message chains;
- yes, we should distinguish start/finish events because we don’t need to measure them;
- we can use
std::jthread.
As said, we need to implement both an event queue and a dispatcher binder. The former will serve to – literally – push events to our designated data structure (a message chain), the latter will serve to – literally – bind any agent to our message queue. For simplicity, we implement both the interfaces into the same class, but this is not required in general.
The custom event queue
The first part of our implementation contains the definition of the functions declared in the event_queue_t interface:
-
push(execution_demand_t) -
push_evt_start(execution_demand_t) -
push_evt_finish(execution_demand_t) noexcept
In other words, these functions enable us to customize how (and where) events are stored when they are transmitted from a sender (e.g. so_5::send) to a receiver (e.g. an agent) that is bound to our event queue. The particular execution_demand_t represents an event ready to be executed, encapsulating all its information, including the agent, the message limit, the message box, the message type, the message payload and, finally, the event handler that can be called.
An important observation: if any event is pushed to the event queue, it means all the filtering and limiting stuff has been done already by SObjectizer. Pushing an event to the queue is like saying “this event must be delivered to the agent”. The agent then will eventually either handle the message or discard it if the agent does not process this type of message in the current state (however, this check is its responsibility and it’s done by SObjectizer behind the scenes). Also, we don’t really need to deal with all the above-mentioned information to execute the event handler. Instead, we can just call this function:
demand.call_handler(thread_id);
We’ll get back to this in a moment.
We start from this skeleton:
class service_time_estimator_dispatcher : public so_5::event_queue_t
{
public:
void push(so_5::execution_demand_t demand) override
{
}
void push_evt_start(so_5::execution_demand_t demand) override
{
}
void push_evt_finish(so_5::execution_demand_t demand) noexcept override
{
}
};
We have opted to employ message chains for storing our events, distinguishing between two types: one for “ordinary” events and a dedicated chain for start and stop events. This approach allows the dequeue strategy to differentiate between the two flavors:
class service_time_estimator_dispatcher : public so_5::event_queue_t
{
public:
void push(so_5::execution_demand_t demand) override
{
so_5::send<so_5::execution_demand_t>(m_event_queue, std::move(demand));
}
void push_evt_start(so_5::execution_demand_t demand) override
{
so_5::send<so_5::execution_demand_t>(m_start_finish_queue, std::move(demand));
}
void push_evt_finish(so_5::execution_demand_t demand) noexcept override
{
so_5::send<so_5::execution_demand_t>(m_start_finish_queue, std::move(demand));
}
private:
so_5::mchain_t m_event_queue;
so_5::mchain_t m_start_finish_queue;
};
That’s it for the event queue, for now.
At this point, we expect that somehow we have a worker thread that dequeues events and executes the execution_demand_t instances as we have already introduced before:
demand.call_handler(thread_id);
The custom dispatcher binder
Next, we put our hands on the dispatcher binder interface that consists of these functions:
-
preallocate_resources(agent_t&) -
undo_preallocation(agent_t&) noexcept -
bind(agent_t&) noexcept -
unbind(agent_t&) noexcept
Without delving into unnecessary details, these functions primarily serve the purpose of assigning the event queue (e.g. our custom event queue) to an agent and, in case, providing the customization points for preallocating resources (e.g. a thread pool) and cleaning up. In case of troubles with the cooperation registration, possible preallocated resources can be cleaned up with undo_preallocation() that would be called. Also, unbind() is called when the cooperation gets deregistered. From our side, we only need to customize bind() so we’ll leave the others empty:
class service_time_estimator_dispatcher : public so_5::event_queue_t, public so_5::disp_binder_t
{
public:
void push(so_5::execution_demand_t demand) override
{
so_5::send<so_5::execution_demand_t>(m_event_queue, std::move(demand));
}
void push_evt_start(so_5::execution_demand_t demand) override
{
so_5::send<so_5::execution_demand_t>(m_start_finish_queue, std::move(demand));
}
void push_evt_finish(so_5::execution_demand_t demand) noexcept override
{
so_5::send<so_5::execution_demand_t>(m_start_finish_queue, std::move(demand));
}
void preallocate_resources(so_5::agent_t&) override
{
}
void undo_preallocation(so_5::agent_t&) noexcept override
{
}
void bind(so_5::agent_t& agent) noexcept override
{
agent.so_bind_to_dispatcher(*this);
}
void unbind(so_5::agent_t&) noexcept override
{
}
private:
so_5::mchain_t m_event_queue;
so_5::mchain_t m_start_finish_queue;
};
At this point, we simply need to spawn the worker thread responsible for dequeuing and processing events. We do that in the constructor, together with the creation of both the message chains:
class service_time_estimator_dispatcher : public so_5::event_queue_t, public so_5::disp_binder_t
{
public:
service_time_estimator_dispatcher(so_5::environment_t& env)
: m_event_queue(create_mchain(env)), m_start_finish_queue(create_mchain(env))
{
m_worker = std::jthread{ [this] {
// ... process
} };
}
// ... as before
private:
std::jthread m_worker;
so_5::mchain_t m_event_queue;
so_5::mchain_t m_start_finish_queue;
};
Now there is an interesting feature of SObjectizer we can leverage: receiving from multiple message chains within the same statement. Indeed, the worker thread might receive both ordinary and start/finish events. In essence, instead of using receive, we use select + receive_case that are two ergonomic features of SObjectizer for receiving from message chains. The code speaks for itself:
m_worker = std::jthread{ [this] {
select(so_5::from_all().handle_all(),
receive_case(m_event_queue, [this](so_5::execution_demand_t d) {
// ...
}),
receive_case(m_start_finish_queue, [](so_5::execution_demand_t d) {
// ...
})
);
} };
This allows it to receive simultaneously from several message chains until they are closed. Every receive_case should contain all the relevant handlers for a given chain. However, if the same message chain is used in multiple receive_case statements, the behavior is undefined.
We have finally reached our target! In fact, we can profile and execute every execution demand in the receive_case of m_event_queue:
m_worker = std::jthread{ [this] {
const auto thread_id = so_5::query_current_thread_id();
select(so_5::from_all().handle_all(),
receive_case(m_event_queue, [this, thread_id](so_5::execution_demand_t d) {
const auto tic = std::chrono::steady_clock::now();
d.call_handler(thread_id);
const auto toc = std::chrono::steady_clock::now();
const auto elapsed = std::chrono::duration<double>(toc - tic).count();
}),
receive_case(m_start_finish_queue, [thread_id](so_5::execution_demand_t d) {
d.call_handler(thread_id);
})
);
} };
Since execution_demand::call_handler() needs a thread id, we simply retrieved and used that of the worker thread. At this point, we implement the above-mentioned feature of this dispatcher: calculating the average elapsed times over an expected number of measures. This can be done in many different ways, we propose one that accumulates the elapsed times and eventually calculates the average by dividing that number by the expected measure counter. To communicate results to the outside, we pass an output channel to the dispatcher (some frameworks provide predefined channels for this stuff, such as Akka’s EventStream).
However, this implementation has a subtle bug spotted by Yauheni: in essence, dispatchers must guarantee that the start event is delivered before every other message and that after the finish event no other messages are dispatched to the agent. This implementation does not really guarantee these two conditions because data can arrive to the input channel of an agent even before it’s bound to the event queue. As Yauheni pointed out while reviewing this article:
- the agent subscribes to some messages in
so_define_agent(at that moment the agent is not yet bound to the event queue); - the agent is bound to the event queue and the start event demand is stored into the special message chain. But the select doesn’t yet waked up;
- a message is sent to the agent at this moment. Since the agent is bound to the event queue, the message will be stored in ordinary message chain;
- the dispatcher finally wakes up and executes
select(). A demand from the ordinary message chain is extracted first, and only then the start event demand.
Thus, there exist several ways to solve this problem. Since Yauheni suggested three different versions, we present here that we think it’s the most interesting. Basically, we get rid of select and split reception on the two types of message chains:
m_worker = std::jthread{ [this] {
const auto thread_id = so_5::query_current_thread_id();
// Step 1. Receive and handle evt_start.
receive(from(m_start_finish_queue).handle_n(1), [thread_id, this](so_5::execution_demand_t d) {
d.call_handler(thread_id);
});
// Step 2. Handle all ordinary messages until m_event_queue is closed.
receive(from(m_event_queue).handle_n(messages_count), [thread_id, this](so_5::execution_demand_t d) {
const auto tic = std::chrono::steady_clock::now();
d.call_handler(thread_id);
const auto toc = std::chrono::steady_clock::now();
const auto elapsed = std::chrono::duration<double>(toc - tic).count();
});
// Step 3. Receive and handle evt_finish.
receive(from(m_start_finish_queue).handle_n(1), [thread_id, this](so_5::execution_demand_t d) {
d.call_handler(thread_id);
});
} };
In addition, as noted by Yauheni, there is another interesting side-effect in this approach: m_event_queue_start_stop can hold no more than 2 demands, this means we can use a fixed-size chain with preallocated storage. We don’t do this now but it was worth sharing.
The full implementation is here below (we have just added the total average calculation and sending, after receiving all the messages in the intermediate step):
class service_time_estimator_dispatcher : public so_5::event_queue_t, public so_5::disp_binder_t
{
public:
service_time_estimator_dispatcher(so_5::environment_t& env, so_5::mbox_t output, unsigned messages_count)
: m_event_queue(create_mchain(env)), m_start_finish_queue(create_mchain(env)), m_output(std::move(output)), m_messages_count(messages_count), m_messages_left(messages_count)
{
m_worker = std::jthread{ [this] {
const auto thread_id = so_5::query_current_thread_id();
receive(from(m_start_finish_queue).handle_n(1), [thread_id, this](so_5::execution_demand_t d) {
d.call_handler(thread_id);
});
receive(from(m_event_queue).handle_n(messages_count), [thread_id, this](so_5::execution_demand_t d) {
const auto tic = std::chrono::steady_clock::now();
d.call_handler(thread_id);
const auto toc = std::chrono::steady_clock::now();
m_total_elapsed += std::chrono::duration<double>(toc - tic).count();
});
so_5::send<double>(m_output, m_total_elapsed / messages_count);
receive(from(m_start_finish_queue).handle_n(1), [thread_id, this](so_5::execution_demand_t d) {
d.call_handler(thread_id);
});
} };
}
void push(so_5::execution_demand_t demand) override
{
so_5::send<so_5::execution_demand_t>(m_event_queue, std::move(demand));
}
void push_evt_start(so_5::execution_demand_t demand) override
{
so_5::send<so_5::execution_demand_t>(m_start_finish_queue, std::move(demand));
}
void push_evt_finish(so_5::execution_demand_t demand) noexcept override
{
so_5::send<so_5::execution_demand_t>(m_start_finish_queue, std::move(demand));
}
void preallocate_resources(so_5::agent_t&) override
{
}
void undo_preallocation(so_5::agent_t&) noexcept override
{
}
void bind(so_5::agent_t& agent) noexcept override
{
agent.so_bind_to_dispatcher(*this);
}
void unbind(so_5::agent_t&) noexcept override
{
}
private:
std::jthread m_worker;
so_5::mchain_t m_event_queue;
so_5::mchain_t m_start_finish_queue;
so_5::mbox_t m_output;
double m_total_elapsed = 0.0;
};
The last missing thing is how to create this instance and pass it to the cooperation. Well, the idiomatic way consists in adding a static factory function into the dispatcher:
[[nodiscard]] static so_5::disp_binder_shptr_t make(so_5::environment_t& env, so_5::mbox_t output, unsigned messages_count)
{
return std::make_shared<service_time_estimator_dispatcher>(env, std::move(output), messages_count);
}
We can finally create a new test using our dispatcher:
TEST(performance_tests, image_resizer_service_time)
{
constexpr unsigned messages_count = 1000;
so_5::wrapped_env_t sobjectizer;
auto& env = sobjectizer.environment();
auto input_channel = env.create_mbox();
auto output_channel = env.create_mbox();
const auto measure_output = so_5::create_mchain(env);
const auto measuring_dispatcher = service_time_estimator_dispatcher::make(env, measure_output->as_mbox(), messages_count);
env.introduce_coop(measuring_dispatcher, [&](so_5::coop_t& coop) {
coop.make_agent<image_resizer>(input_channel, output_channel, 4);
});
const auto test_frame = cv::imread("test_data/replay/1.jpg");
for (auto i = 0u; i < messages_count; ++i)
{
so_5::send<cv::Mat>(input_channel, test_frame);
}
receive(from(measure_output).handle_n(1), [](double service_time_avg) {
std::cout << std::format("image_resizer average service time calculated on {} frames is: {}s\n", messages_count, service_time_avg);
});
}
On my machine (Intel i7-11850H @2.50GHz, 8 Cores), this test consistently outputs between 0,00099s (<1ms) and 0,0011s (1.1ms), that is aligned with a maximum throughput of ~900 fps we measured in the previous post (remember that the calculation of the maximum throughput includes other costs such as sending and waiting time).
Take into account that the method for calculating the average service time is simplistic and may not be suitable in certain cases. Nevertheless, given that you are now aware of where the measurement can occur, you can employ other approaches to make this measurement.
An implementation detail
When I showed this dispatcher to Yauheni for the first time, he got back to me with a main point: “you’ll have a copy of execution_demand_t on every call. Because execution_demand_t is not a small object (it holds 3 raw pointers, a std::type_index, 64-bit mbox_id_t and reference-counting message_ref_t) the copying can have an impact on the performance”. He was pointing to this part:
m_worker = std::jthread{ [this] {
const auto thread_id = so_5::query_current_thread_id();
select(so_5::from_all().handle_all(),
receive_case(m_event_queue, [this, thread_id](so_5::execution_demand_t d) {
// ...
d.call_handler(thread_id);
// ...
}),
// ...
);
} };
Since execution_demand_t::call_handler() is non-const, we need a copy of the execution_demand_t to invoke that function.
Certainly, as this dispatcher is primarily used for measuring service time in a test bench, our focus is not on micro-optimization. Nonetheless, Yauheni’s suggestion is useful to introduce another feature of SObjectizer which we’ll delve into in a future post to avoid taking on too much at once.
Service time with multiple threads
In the previous post we mentioned that distributing image_resizer‘s work across multiple workers degrades performance a bit because of the contention of the CPU, since cv::resize is already trying to exploit several cores.
Can we observe this issue on the service time?
Partially. We can only see the effect of multiple image_resizer instances executing their logic (that is mainly cv::resize) simultaneously. The test with two agents is performed by instantiating two cooperations that use two different instances of our new dispatcher:
TEST(performance_tests, two_image_resizers_in_parallel)
{
constexpr unsigned messages_count = 100;
so_5::wrapped_env_t sobjectizer;
auto& env = sobjectizer.environment();
auto input_channel = env.create_mbox();
auto output_channel = env.create_mbox();
auto measure_output1 = so_5::create_mchain(env);
auto measure_output2 = so_5::create_mchain(env);
env.introduce_coop(service_time_estimator_dispatcher::make(env, measure_output1->as_mbox(), messages_count), [&](so_5::coop_t& coop) {
coop.make_agent<image_resizer>(input_channel, output_channel, 4);
});
env.introduce_coop(service_time_estimator_dispatcher::make(env, measure_output2->as_mbox(), messages_count), [&](so_5::coop_t& coop) {
coop.make_agent<image_resizer>(input_channel, output_channel, 4);
});
const auto test_frame = cv::imread("test_data/replay/1.jpg");
for (auto i = 0u; i < messages_count; ++i)
{
so_5::send<cv::Mat>(input_channel, test_frame);
}
receive(from(measure_output1).handle_n(1), [](double service_time_avg) {
std::cout << std::format("image_resizer(1) average service time calculated on {} frames is: {:.5f}s\n", messages_count, service_time_avg);
});
receive(from(measure_output2).handle_n(1), [](double service_time_avg) {
std::cout << std::format("image_resizer(2) average service time calculated on {} frames is: {:.5f}s\n", messages_count, service_time_avg);
});
}
As you see, even though we send test frames only to input_channel, each agent receives its own copy of that instance. This is not equivalent to distributing the input images across multiple workers since, in that case, every frame would be processed by exactly one worker.
Yet, we get a qualitative idea of the situation and, indeed, on my machine I obtain interesting results:
image_resizer(1) average service time calculated on 100 frames is: 0.00201s
image_resizer(2) average service time calculated on 100 frames is: 0.00219s
In simpler terms, the service time of the two agents in this test is approximately twice the service time of the agent in the single-threaded test. This suggests that CPU contention and context switching are somewhat confirmed by this qualitative experiment. However, it’s important to note that this only arouses our suspicions, opening the door to further investigations. It’s not a comprehensive profiling.
Final remarks
The presented approach only works when we need to measure the average time to react to a certain message by an agent. Indeed, a dispatcher works by dequeuing events and executing handlers. However, it does not work, for example, if the agent is stuck in a blocking receive like image_saver_worker:
void so_evt_start() override
{
receive(from(m_input).handle_all(), [this](const cv::Mat& image) {
imwrite((m_root_folder / std::format("image_{}_{}.jpg", m_worker_id, m_counter++)).string(), image);
});
}
In this scenario, the dispatcher solely executes the “start event” which will lead the executing thread to be blocked until the receive operation is completed, presumably during the shutdown.
After all, service_time_estimator_dispatcher is effective only when events are naturally handled by the agent under test. In essence, SObjectizer can’t be of much help if events can’t be “sampled”.
In cases such as image_saver_worker, one intrusive option is to include profiling information into the agent, possibly under some configuration toggle. Another approach, if feasible, involves refactoring the agent to decouple the reception and handling of messages. This allows for the reestablishment of a flow of events that can be sampled more naturally.
Another point worth mentioning is that measuring service time in isolation is typically necessary only to benchmark the optimal performance of a specific operation, helping to understand if certain requirements can be technically satisfied in relation to a target throughput. For example, if a certain agent is required to process at rate of 50 fps, either its service time should not be higher than 20 milliseconds on average or we find a work distribution schema that makes the target throughput sustainable. However, in a real system, as we have seen, the actual performance of what was measured in isolation can vary substantially due to several factors, including the contention for the same set of computational resources and context switching. Additionally, performance requirements are generally set on the whole pipeline rather than on specific agents.
There is also another indicator that we have somewhat ignored: waiting time. As mentioned earlier, waiting time mainly depends on the dispatcher. When service time is not a concern but throughput is suspiciously below expectations, waiting time might be investigated. Sometimes, this leads to tuning or replacing the dispatcher, or even – as a drastic decision – rolling out a custom implementation. This is relevant in SObjectizer as it differs from other frameworks: multiple agents can share the very same message queue, or one agent can have its messages hosted on multiple queues. Also, the threading strategy varies. It all depends on the dispatcher. Thus, the waiting time of each message is influenced by how agents are bound to dispatchers.
By knowing throughput and service time we can approximate waiting time, however the exact calculation should be done inside the dispatcher. Technically speaking, waiting time is the difference between the moment a message is pushed to the queue and the moment it’s dequeued, just before executing the corresponding handler. However, SObjectizer does not provide this calculation within its dispatchers.
Takeaway
In this episode we have learned:
- service time represents how fast messages are processed by the agent;
- to calculate service time in isolation, an approach consists in rolling out a custom dispatcher that enables us to time the execution of an event handler;
- this approach only works when handling of messages is done through agent subscriptions as events must be “sampled” by the dispatcher;
- commonly in SObjectizer, a dispatcher is the combination of an event queue and a dispatcher binder. To implement these two, we must implement two interfaces;
- a custom event queue must implement
event_queue_tand defines the strategy to accumulate new events to be processed; - a custom dispatcher binder must implement
disp_binder_tand its main role is to bind an agent to an event queue (e.g. the custom event queue); - the rest of the details should define how events are dequeued from the event queue and processed, by executing handlers on some thread (e.g. a single thread, a thread pool);
-
select+receive_caseis an idiom to receive from multiple message chains within the same statement; - a message chain can’t appear in more than one
receive_case, otherwise the behavior is undefined; - typically, measuring service time in isolation is useful to benchmark the optimal performance of a specific operation, however the number may vary when calculated within the real system;
- waiting time is another metric that might be useful to investigate if the dispatcher in use fits our needs, however it can only be approximated.
As usual, calico is updated and tagged.
What’s next?
In the upcoming article, our discussion with Helen about performance will wrap up as we delve into typical benchmarks for actor frameworks and share some experiments conducted with SObjectizer.
Thanks to Yauheni Akhotnikau for having reviewed this post.




Top comments (0)