
The deep dive into performance is reaching its conclusion, and in this final part, we will delve into a few typical benchmarks of actor model frameworks, applying these concepts to SObjectizer. Also, after reading this article, we will have some more understanding of the hidden costs of the framework and some tuning options which are available.
First of all, regardless of internal details and design decisions, in-process actor model frameworks commonly share some fundamental features:
- creation, destruction, and management of agents;
- message delivery;
- thread management.
Thus, benchmarks typically assess:
- performance of creating and destroying agents;
- performance of message passing in both 1:1 and 1:N scenarios;
- above benchmarks applied in both single- and multi-threaded cases.
SObjectizer provides some benchmarks in this official folder. Also, there is an old but still interesting discussion about comparing performance of SObjectizer and CAF that explores some benchmarks here.
Skynet: performance of managing agents
The initial benchmark reveals the overhead of creating and destroying agents, which may seem marginal but is significant in some scenarios. This test provides insights into the implicit cost of agent management in SObjectizer. It’s crucial to note that agents in SObjectizer possess features tailored for structuring work in concurrent applications. Agents can have states, define subscriptions, and are organized in cooperations. Therefore, they come with a certain cost for a reason. Dynamically spawning thousands of agents might pose a challenge, and this benchmark is designed to illustrate this aspect.
We propose the Skynet benchmark that consists in creating an agent which spawns 10 new agents, each of them spawns 10 more agents, and so on, until one million agents are created on the final level. Then, each of them returns back its ordinal number (from 0 to 999999), which are summed on the previous level and sent back upstream, until reaching the root (the answer should be 499999500000):
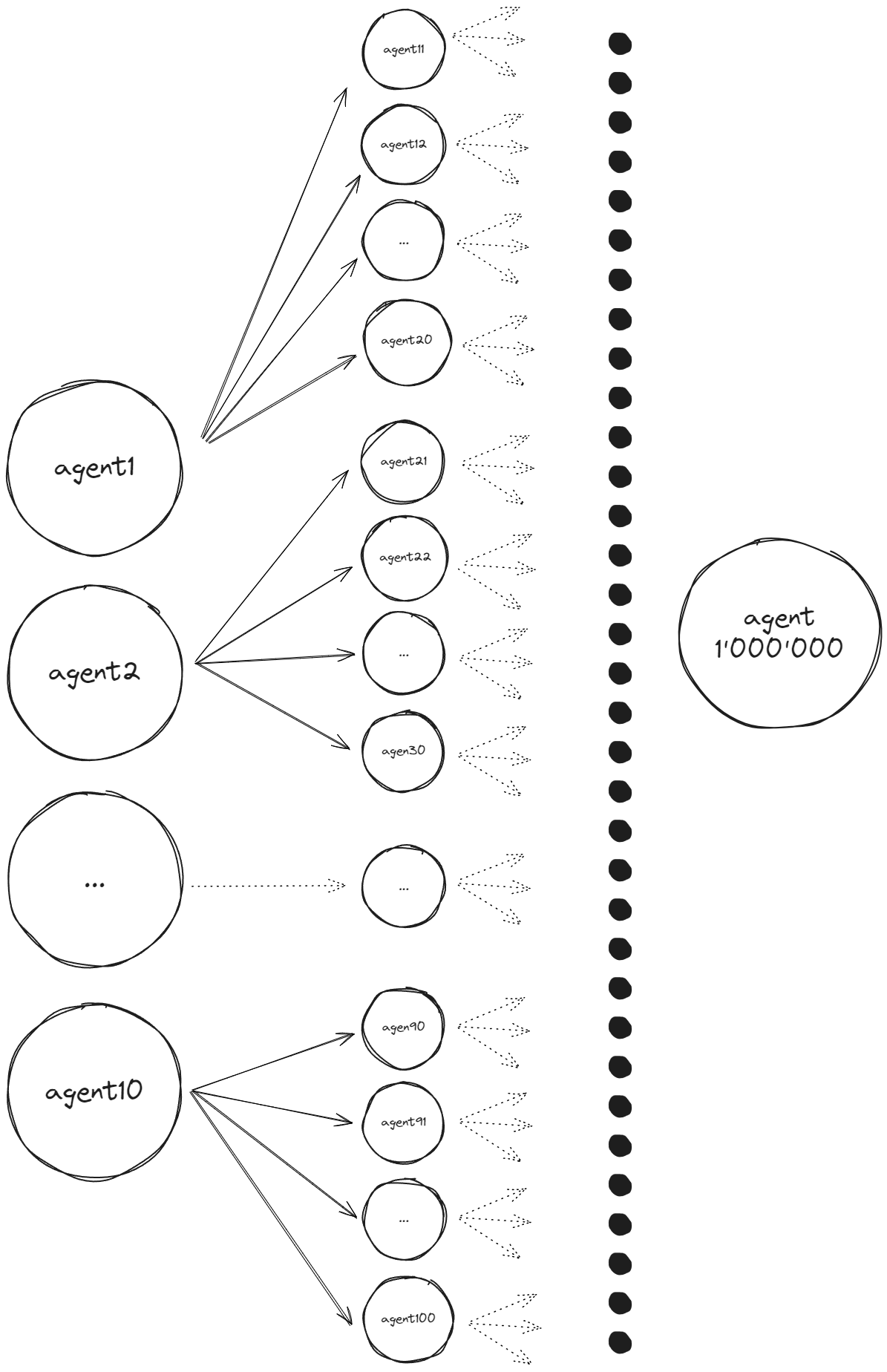
Disclaimer: don’t use this benchmark to compare different concurrent entities like “futures vs actors”, as the complaints here and here rightly highlight. It does not make any sense.
As you can imagine, every computation of agents in this test is a “no-op”, since the primary focus is on measuring the cost of spawning agents and exchanging (a few) control messages. The benchmark measures the wall time of the whole experiment (the elapsed total time).
A possible implementation is here below:
class skynet final : public so_5::agent_t
{
public:
skynet(so_5::agent_context_t ctx, so_5::mbox_t parent, size_t num, size_t size)
: agent_t(ctx), m_parent(std::move(parent)), m_num(num), m_size(size)
{}
void so_evt_start() override
{
if (1u == m_size)
{
so_5::send<size_t>(m_parent, m_num);
}
else
{
so_subscribe_self().event([this](size_t v) {
m_sum += v;
if (++m_received == divider)
{
so_5::send<size_t>(m_parent, m_sum);
}
});
so_environment().introduce_coop([&](so_5::coop_t& coop) {
const auto sub_size = m_size / divider;
for (unsigned int i = 0; i != divider; ++i)
{
coop.make_agent<skynet>(so_direct_mbox(), m_num + i * sub_size, sub_size);
}
});
}
}
private:
static inline size_t divider = 10;
const so_5::mbox_t m_parent;
const size_t m_num;
const size_t m_size;
size_t m_sum = 0;
unsigned int m_received = 0;
};
TEST(benchmarks, skynet)
{
const so_5::wrapped_env_t sobjectizer;
const auto output = create_mchain(sobjectizer.environment());
const auto tic = std::chrono::steady_clock::now();
sobjectizer.environment().introduce_coop([&](so_5::coop_t& c) {
c.make_agent<skynet>(output->as_mbox(), 0u, 1000000u);
});
size_t result = 0;
receive(from(output).handle_n(1), [&](size_t i) {
result = i;
});
std::cout << std::chrono::duration<double>(std::chrono::steady_clock::now() - tic) << "\n";
EXPECT_THAT(result, testing::Eq(499999500000));
}
On my machine (Intel i7-11850H @2.50GHz, 8 Cores), this test outputs consistently between 1.45s and 1.6s. However, it does not include agents deregistration time. The time approximately doubles if we include that cost:
TEST(benchmarks, skynet_with_deregistration)
{
std::chrono::steady_clock::time_point tic;
{
const so_5::wrapped_env_t sobjectizer;
const auto output = create_mchain(sobjectizer.environment());
tic = std::chrono::steady_clock::now();
sobjectizer.environment().introduce_coop([&](so_5::coop_t& c) {
c.make_agent<skynet>(output->as_mbox(), 0u, 1000000u);
});
size_t result = 0;
receive(from(output).handle_n(1), [&](size_t i) {
result = i;
});
EXPECT_THAT(result, testing::Eq(499999500000));
}
std::cout << std::chrono::duration<double>(std::chrono::steady_clock::now() - tic) << "\n";
}
At this point, we can see the impact of multiple threads by employing another dispatcher such as a thread_pool dispatcher:
class skynet_tp final : public so_5::agent_t
{
public:
skynet_tp(so_5::agent_context_t ctx, so_5::disp::thread_pool::dispatcher_handle_t disp, so_5::mbox_t parent, size_t num, size_t size)
: agent_t(std::move(ctx)), m_disp(std::move(disp)), m_parent(std::move(parent)), m_num(num), m_size(size)
{}
void so_evt_start() override
{
if (1u == m_size)
{
so_5::send< size_t >(m_parent, m_num);
}
else
{
so_subscribe_self().event([this](size_t v) {
m_sum += v;
if (++m_received == divider)
{
so_5::send< size_t >(m_parent, m_sum);
}
});
so_environment().introduce_coop(
m_disp.binder(so_5::disp::thread_pool::bind_params_t{}.fifo(so_5::disp::thread_pool::fifo_t::cooperation)),
[&](so_5::coop_t& coop) {
const auto sub_size = m_size / divider;
for (unsigned int i = 0; i != divider; ++i)
{
coop.make_agent<skynet_tp>(m_disp, so_direct_mbox(), m_num + i * sub_size, sub_size);
}
});
}
}
private:
static inline size_t divider = 10;
const so_5::disp::thread_pool::dispatcher_handle_t m_disp;
const so_5::mbox_t m_parent;
const size_t m_num;
const size_t m_size;
size_t m_sum = 0;
size_t m_received = 0;
};
TEST(benchmarks, skynet_thread_pool)
{
constexpr size_t thread_pool_size = 2;
std::chrono::steady_clock::time_point tic;
{
const so_5::wrapped_env_t sobjectizer;
const auto output = create_mchain(sobjectizer.environment());
tic = std::chrono::steady_clock::now();
sobjectizer.environment().introduce_coop([&](so_5::coop_t& coop) {
coop.make_agent<skynet_tp>(so_5::disp::thread_pool::make_dispatcher(sobjectizer.environment(), thread_pool_size), output->as_mbox(), 0u, 1000000u);
});
size_t result = 0u;
receive(from(output).handle_n(1), [&result](size_t v) {
result = v;
});
EXPECT_THAT(result, testing::Eq(499999500000));
}
std::cout << std::chrono::duration<double>(std::chrono::steady_clock::now() - tic) << "\n";
}
Some numbers taken by changing both the size of the pool and the type of fifo strategy:
| pool size | cooperative | individual |
|---|---|---|
| 1 | 5.0s | 5.0s |
| 2 | 4.1s | 5.1s |
| 3 | 3.7s | 5.6s |
| 4 | 3.8s | 7.1s |
| 8 | 4.2s | 14.5s |
comparing different pool size and fifo strategies of skynet
Clearly, the elapsed time here includes also the cost of managing the thread pool, for this reason is higher than the single-threaded version.
In a private conversation, Yauheni briefly commented on the cost of agent and cooperation management: “the cost of registration/deregistration of cooperations in SObjectizer was always considerably big in comparison with alternatives. There were reasons for that: cooperations are separate objects, so in SObjectizer you have to create an agent (paying some price) and you have to create a cooperation (paying some price). Registration requires binding of an agent to a dispatcher (paying some price) and there is a cost you pay for the transaction – binding has to be dropped if something is going wrong (like an exception from so_define_agent()). Deregistration is a complex and asynchronous procedure that requires sending evt_finish event and placing the coop to the queue of coops for the final deregistration. It’s necessary to correctly join worker threads if they are allocated for agents from the cooperation, so paying some price again”.
Yauheni also highlighted that having too many agents is an observability nightmare, not just for debugging but also for monitoring performance indicators. Restricting the number of agents to a few hundred thousand shows a notable improvement. In fact, the single-threaded skynet with 100,000 agents takes between 25 to 29 milliseconds (including the destruction of agents).
Finally, consider scenarios where a significant number of agents are spawned at the startup of the application, as in the case of calico. In such scenarios, agents are created dynamically (e.g., from a configuration file) when the application starts, staying up and running for the rest of the time to handle messages.
Ping pong: performance of 1:1 messaging
When it comes to benchmarking one to one message passing performance, the “ping pong” benchmark is a classic. In this benchmark, two agents engage in an exchange of messages for a predefined number of iterations. The “pinger” agent sends a “ping” message and awaits a corresponding “pong” before sending another “ping.” Similarly, the “ponger” agent responds with a “pong” only after receiving a “ping.” This back-and-forth messaging continues for the specified number of times:
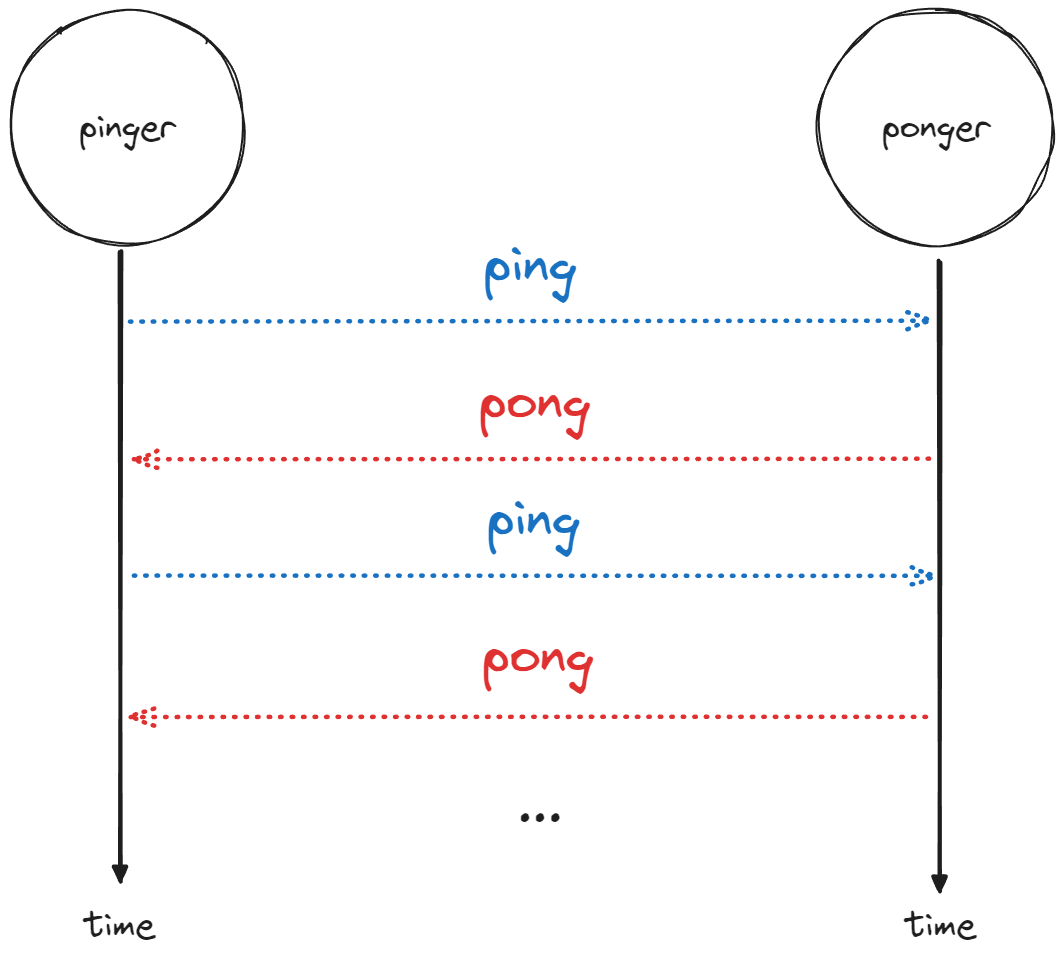
The “pinger” agent estimates the throughput by calculating the rate at which messages are exchanged, obtained by dividing the elapsed time by the number of iterations (likewise we did in our frequency_calculator from the first article of the performance series).
The benchmark becomes particularly insightful in two scenarios:
- single-threaded execution: when both agents operate on a shared thread. This configuration highlights the efficiency of the message queue with only one worker thread, unaffected by external influences;
- multi-threaded execution: when both agents run on separate threads. In this case, the benchmark serves as a means to measure the latency of message transmission between two working threads. The observed latency can vary depending on the synchronization mechanisms used by the worker threads and expectations regarding empty queues (aka: the dispatcher).
As threading is up to the dispatcher, the code for both will be almost the same. Here is the code of the first scenario:
struct ping_signal final : so_5::signal_t{};
struct pong_signal final : so_5::signal_t{};
class pinger final : public so_5::agent_t
{
public:
pinger(so_5::agent_context_t ctx, unsigned count)
: agent_t(std::move(ctx)), m_pings_count(count), m_pings_left(count)
{
}
void set_ponger_channel(so_5::mbox_t other)
{
m_ponger_channel = std::move(other);
}
void so_define_agent() override
{
so_subscribe_self().event([this](so_5::mhood_t<pong_signal>) {
send_ping();
});
}
void so_evt_start() override
{
m_start = std::chrono::steady_clock::now();
send_ping();
}
private:
void send_ping() {
if (m_pings_left)
{
so_5::send<ping_signal>(m_ponger_channel);
--m_pings_left;
}
else
{
const auto diff = std::chrono::duration<double>(std::chrono::steady_clock::now() - m_start);
const auto freq = m_pings_count / diff.count();
std::cout << std::format("ping-pong count={} throughput={:.2f} mex/s real-throughput={:.2f} mex/s\n", m_pings_count, freq, freq*2);
so_environment().stop();
}
}
std::chrono::time_point<std::chrono::steady_clock> m_start;
unsigned m_pings_count;
unsigned m_pings_left;
so_5::mbox_t m_ponger_channel;
};
class ponger final : public so_5::agent_t
{
public:
ponger(so_5::agent_context_t ctx)
: agent_t(std::move(ctx))
{
}
void set_pinger_channel(so_5::mbox_t other)
{
m_pinger_channel = std::move(other);
}
void so_define_agent() override
{
so_subscribe_self().event([this](so_5::mhood_t<ping_signal>) {
so_5::send<pong_signal>(m_pinger_channel);
});
}
private:
so_5::mbox_t m_pinger_channel;
};
TEST(benchmarks, ping_pong_single_thread)
{
so_5::launch([](so_5::environment_t& env) {
env.introduce_coop([&](so_5::coop_t& coop) {
const auto pinger_agent = coop.make_agent<pinger>(100000);
const auto ponger_agent = coop.make_agent<ponger>();
pinger_agent->set_ponger_channel(ponger_agent->so_direct_mbox());
ponger_agent->set_pinger_channel(pinger_agent->so_direct_mbox());
});
});
}
A few details:
- we utilized
so_5::launch, a self-contained function that executes a SObjectizer environment and keeps it active until explicitly halted (done whenpinger::send_ping()is completed); - it was needed to set the output channel of both agents in order to use their direct message box (that is Multiple-Producer Single-Consumer channel);
- the test reports both “throughput” and “real-throughput,” with the latter being twice the former. This is because the message exchange effectively involves twice the count (since each ping is accompanied by a pong), making the “real” throughput double. Typically, the “real” throughput is considered the reference number.
On my machine, this benchmark outputs something like this:
ping-pong count=100000 elapsed=0.0115244s throughput=8677241.33 mex/s real-throughput=17354482.66 mex/s
In other words, on my machine, the maximum “ping-pong throughput” is approximately 17 million messages per second. Typically, when you hear something like “this framework’s maximum throughput is X million messages per second”, it comes from a benchmark like this.
At this point, we might change the dispatcher to active_obj in order to give each agent its own worker thread. Here is the only piece of code to change:
so_5::launch([](so_5::environment_t& env) {
env.introduce_coop(so_5::disp::active_obj::make_dispatcher(env).binder(), [&](so_5::coop_t& coop) {
const auto pinger_agent = coop.make_agent<pinger>(100000);
const auto ponger_agent = coop.make_agent<ponger>();
pinger_agent->set_ponger_channel(ponger_agent->so_direct_mbox());
ponger_agent->set_pinger_channel(pinger_agent->so_direct_mbox());
});
});
On my machine, the output now changes to something like this:
ping-pong count=100000 elapsed=0.100887s throughput=991207.99 mex/s real-throughput=1982415.97 mex/s
Thus, the maximum throughput is approximately 2 million messages per second.
If we switch to a thread pool with 2 threads and cooperation FIFO (aka: a shared message queue), the performance fits approximately in the middle (10 million per seconds):
ping-pong count=100000 elapsed=0.0197074s throughput=5074236.07 mex/s real-throughput=10148472.15 mex/s
Switching to individual FIFO (aka: each agent has its own message queue), the performance drops to ~1.7 million per second:
ping-pong count=100000 elapsed=0.117929s throughput=847970.72 mex/s real-throughput=1695941.44 mex/s
As we can expect, this is slightly worse than active_obj, presumably because the thread pool management costs a bit more.
The ping pong benchmark can be extended by introducing some work in agents, simulating CPU load, or by adding some sleep to simulate waiting for external resources to be available. Feel free to explore and test other dispatchers and configurations based on your preferences.
Also, it’s worth sharing another version based on “named channels” instead of direct message boxes. In other words, we’ll replace agent’s Multi-Producer Single-Consumer direct channels with arbitrary Multi-Producer Multi-Consumer message boxes:
class pinger_named final : public so_5::agent_t
{
public:
pinger_named(so_5::agent_context_t ctx, unsigned count)
: agent_t(std::move(ctx)), m_pings_count(count), m_pings_left(count), m_ponger_channel(so_environment().create_mbox("ponger"))
{
}
void so_define_agent() override
{
so_subscribe(so_environment().create_mbox("pinger")).event([this](so_5::mhood_t<pong_signal>) {
send_ping();
});
}
void so_evt_start() override
{
m_start = std::chrono::steady_clock::now();
send_ping();
}
private:
void send_ping() {
if (m_pings_left)
{
so_5::send<ping_signal>(m_ponger_channel);
--m_pings_left;
}
else
{
const auto diff = std::chrono::duration<double>(std::chrono::steady_clock::now() - m_start);
const auto freq = m_pings_count / diff.count();
std::cout << std::format("ping-pong count={} elapsed={} throughput={:.2f} mex/s real-throughput={:.2f} mex/s\n", m_pings_count, diff, freq, freq*2);
so_environment().stop();
}
}
std::chrono::time_point<std::chrono::steady_clock> m_start;
unsigned m_pings_count;
unsigned m_pings_left;
so_5::mbox_t m_ponger_channel;
};
class ponger_named final : public so_5::agent_t
{
public:
ponger_named(so_5::agent_context_t ctx)
: agent_t(std::move(ctx)), m_pinger_channel(so_environment().create_mbox("pinger"))
{
}
void so_define_agent() override
{
so_subscribe(so_environment().create_mbox("ponger")).event([this](so_5::mhood_t<ping_signal>) {
so_5::send<pong_signal>(m_pinger_channel);
});
}
private:
so_5::mbox_t m_pinger_channel;
};
TEST(benchmarks, ping_pong_named_channels)
{
so_5::launch([](so_5::environment_t& env) {
env.introduce_coop([&](so_5::coop_t& coop) {
coop.make_agent<pinger_named>(100000);
coop.make_agent<ponger_named>();
});
});
}
The performance are slightly worse than of direct channels but still in the same order of magnitude (16 million messages per second) :
ping-pong count=100000 elapsed=0.0124566s throughput=8027872.77 mex/s real-throughput=16055745.55 mex/s
As expected, there is a performance difference between MPSC (aka: direct message boxes) and MPMC message boxes, however in certain scenarios, it might be negligible. For example, in calico we have two main bottlenecks: the producer constrained by the camera’s frame rate, and possibly some resource-intensive agents (e.g. face_detector) operating in the order of milliseconds. Consequently, in our context, the difference between MPMC and MPSC channels is not significant.
In terms of message sending and processing in SObjectizer, it’s worth mentioning a few considerations that have an impact:
- agents are finite-state machines, necessitating consideration of the agent’s current state during the message handler search;
- agents can subscribe to messages from various mailboxes. Consequently, the process of selecting a handler must account for both the agent’s current state and the associated message mailbox;
- the multi-consumer mailbox feature has some implications for the message dispatching process as the message box has to find all the subscribers for a certain message.
Performance of 1:N messaging
To assess the scenario of 1:N messaging, we design a benchmark closely aligned with our domain. In essence, a potentially fast producer sends data – say 100’000 numbers – to a specific named channel, and multiple agents – say 100 – are subscribed to that channel:
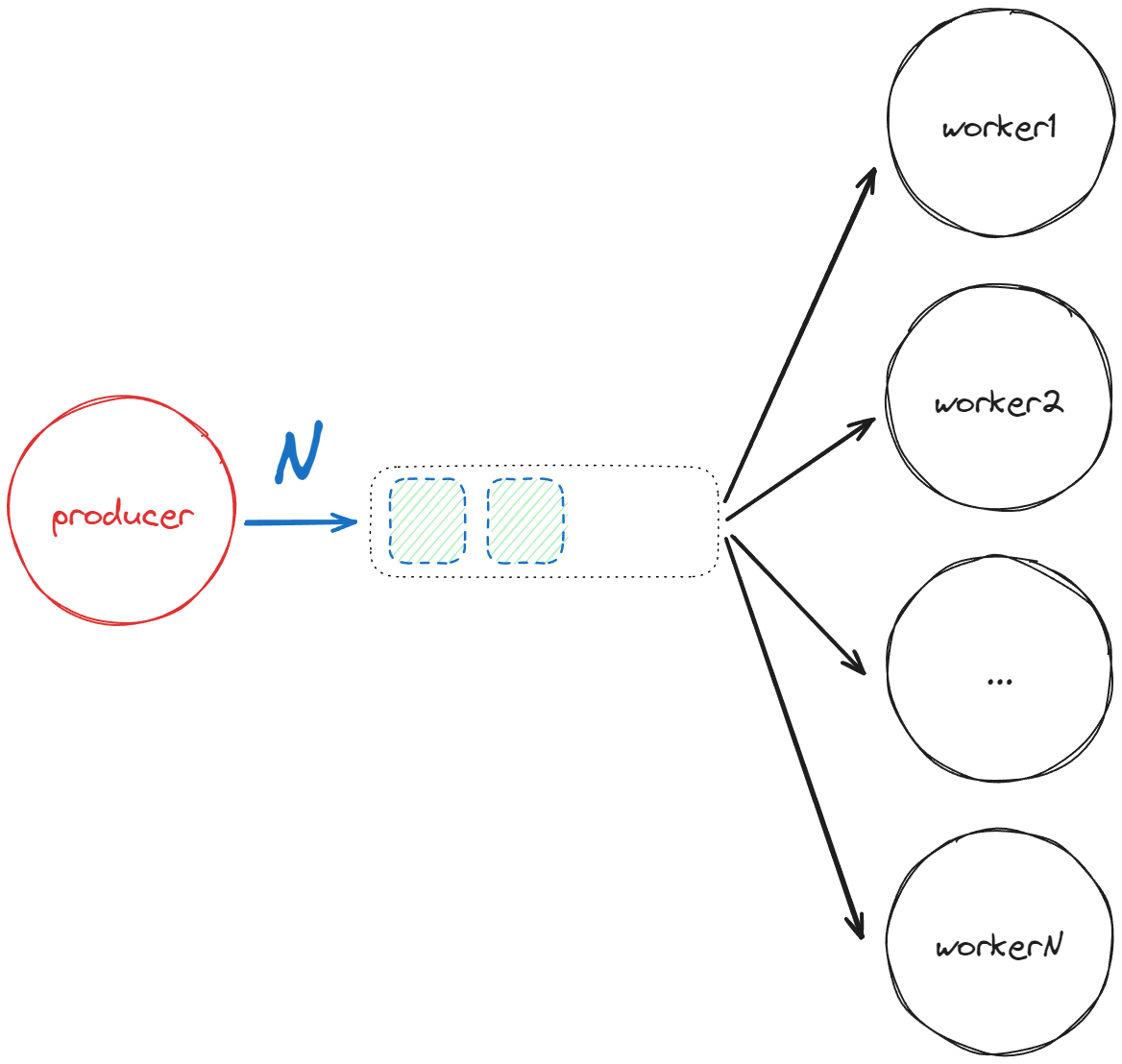
Initially, we use only two threads: one dedicated to the producer and a shared one dedicated to the others. Additionally, in the initial version, there is no work inside agents. Then, in a subsequent version, we introduce some little sleeping before replying to simulate concurrent operations without active CPU utilization (e.g. network usage). Finally, we add some CPU usage.
We create only one cooperation. The producer is bound to the default one_thread dispatcher, whereas the others are bound to an active_group to share the same thread. Also, for simplicity, all agents send back a message to the producer when they have handled all the messages. We measure the wall time of the whole experiment, including agent creation and deregistration, since the number of agents is small (remember the skynet benchmark shows the cost of managing 100’000 agents is less than a tenth of a second):
template<unsigned workers_count>
class producer final : public so_5::agent_t
{
public:
producer(so_5::agent_context_t c, unsigned message_count)
: agent_t(std::move(c)), m_message_count(message_count)
{
}
void so_evt_start() override
{
const auto tic = std::chrono::steady_clock::now();
const auto destination = so_environment().create_mbox("input");
for (unsigned i = 0; i < m_message_count; ++i)
{
so_5::send<unsigned>(destination, i);
}
const auto elapsed = std::chrono::duration<double>(std::chrono::steady_clock::now() - tic).count();
std::cout << std::format("1:N benchmark (message_count={} worker_count={}) => sending data: elapsed={}\n", m_message_count, workers_count, elapsed);
}
void so_define_agent() override
{
so_subscribe_self().event([this](unsigned worker_id) {
m_done_received[worker_id] = true;
if (m_done_received.all())
{
so_environment().stop();
}
});
}
private:
unsigned m_message_count;
std::bitset<workers_count> m_done_received;
};
class worker final : public so_5::agent_t
{
public:
worker(so_5::agent_context_t c, unsigned message_count, unsigned worker_id, so_5::mbox_t dest)
: agent_t(std::move(c)), m_message_count(message_count), m_worker_id(worker_id), m_input(so_environment().create_mbox("input")), m_output(std::move(dest))
{
}
void so_define_agent() override
{
so_subscribe(m_input).event([this](unsigned msg) {
if (--m_message_count == 0)
{
so_5::send<unsigned>(m_output, m_worker_id);
}
});
}
private:
unsigned m_message_count;
unsigned m_worker_id;
so_5::mbox_t m_input;
so_5::mbox_t m_output;
};
TEST(benchmarks, messaging_one_to_many)
{
constexpr auto workers_count = 100;
constexpr auto message_count = 100000;
const auto tic = std::chrono::steady_clock::now();
so_5::launch([](so_5::environment_t& env) {
env.introduce_coop([&](so_5::coop_t& coop) {
const auto master_mbox = coop.make_agent<producer<workers_count>>(message_count)->so_direct_mbox();
const auto workers_dispatcher = so_5::disp::active_group::make_dispatcher(env).binder("workers");
for (auto i = 0u; i < workers_count; ++i)
{
coop.make_agent_with_binder<worker>(workers_dispatcher, message_count, i, master_mbox);
}
});
});
const auto elapsed = std::chrono::duration<double>(std::chrono::steady_clock::now() - tic).count();
std::cout << std::format("1:N benchmark (message_count={} worker_count={}) => overall: elapsed={}\n", message_count, workers_count, elapsed);
}
As you notice, we are also measuring the time taken for the sole sending operation. It will be useful.
On my machine, the benchmark prints something like this:
massive-send send time elapsed=0.6293867 [message_count=100000 worker_count=100]
massive-send elapsed=0.6358283 [message_count=100000 worker_count=100]
At this point, we might wonder how the outcome changes when more threads are involved. We start by replacing the dispatcher with an active_obj that binds each agent to a dedicated thread and event queue. The results:
massive-send send time elapsed=1.8008089 [message_count=100000 worker_count=100]
massive-send elapsed=1.8236707 [message_count=100000 worker_count=100]
Then we use thread pools and see the result. Using 4 threads and cooperation FIFO shows this situation:
massive-send send time elapsed=2.79563 [message_count=100000 worker_count=100]
massive-send elapsed=2.7978501 [message_count=100000 worker_count=100]
Individual FIFO makes performance worse:
massive-send send time elapsed=14.9737671 [message_count=100000 worker_count=100]
massive-send elapsed=14.9762084 [message_count=100000 worker_count=100]
What’s happening?
First of all, we observe sending time is almost equal to the total time in all the benchmarks. This is merely because the agents do nothing (their operations are just no-ops). In other words, we might argue that it takes more to send a single message than to handle it. Indeed, to send a message, SObjectizer will dynamically allocate memory and create a “demand” instance for each subscriber. Using multiple threads will also cause more thread preemption and context switches.
The story does not end here. The performance of individual FIFO is too poor to ignore, prompting us to delve deeper into the issue. At this point, we are ready to meet another advanced option of the thread_pool dispatcher: max_demands_at_once.
This option (officially explained here), determines how often a working thread will switch from one event queue to another. In other words, when a worker thread processes one event from a queue, the parameter max_demands_at_once determines how many events from a queue the thread has to process before switching to another queue. If the queue contains, let’s say, 5 events and max_demands_at_once is 3, the agent first handles 3 events and then moves on to another queue. Evidently, if the queue becomes empty before processing max_demands_at_once events, the thread switches to another non-empty queue.
The interesting fact is that turning max_demands_at_once to 1 on the 4-size individual thread pool dramatically improves the situation:
massive-send send time elapsed=1.4899536 [message_count=100000 worker_count=100]
massive-send elapsed=2.2166388 [message_count=100000 worker_count=100]
As said before, in both the versions the event queues will become empty quickly because processing events is faster than sending them. So, regardless of the value of max_demands_at_once, every worker should frequently switch from a queue to another non-empty queue as the current one will get empty just after processing one event. Thus, it seems that attempting to find a non-empty queue is more resource-intensive than switching to another non-empty queue when one is already being processed.
Without delving too deeply into internal details, Yauheni conducted additional tests and identified some reasons for this scenario. From a high level point of view, imagine there is contention on a lock that protects access to a list of non-empty agents’ queues. A queue is added to this list when it becomes non-empty. Similarly, it’s removed when it becomes empty. The problem is the “frequency” the queues become empty and non-empty, since the lock contention depends on this state change. With max_demands_at_once=4, since messages are handled quickly, the queues will become empty more frequently as every worker will “drain” the queue more quickly and the empty queue has to be removed from the list. And it will be added back to the list on the next “send” iteration. This removal/addition requires frequent lock acquisition. On the other hand, when max_demands_at_once=1, there will be more chances to have some messages left in the agent queues and there is no need to remove a queue from the list (and then add it again), so the list’s lock contention is much lower in that case.
To change this setting, we call the appropriate function on the bind_params_t object:
const auto workers_dispatcher =
so_5::disp::thread_pool::bind_params_t{}
.fifo(so_5::disp::thread_pool::fifo_t::individual)
.max_demands_at_once(1);
Now, we increase the number of workers while decreasing the number of messages:
-
workers_count=10’000 -
message_count=1000
Then, the results change to:
-
active_group: total=1.2458788s (send=1.0891258s) -
thread_pool(size=4, max_demands_at_once=1) individual fifo: 2.2247613s (send=1.1975858s) -
thread_pool(size=4, max_demands_at_once=4) cooperation fifo: 2.600463s (send=2.3765951s) -
thread_pool(size=4, max_demands_at_once=1) cooperation fifo: 2.743429s (send=2.3170744s) -
thread_pool(size=4, max_demands_at_once=4) individual fifo: 22.4349205s (send=22.3840745s) -
active_obj: total=28.9539098s (send=27.6863413s)
As expected, active_group remains the top performer in this scenario, given the absence of any work. However, active_obj emerges as the least favorable option due to the huge number of workers that causes overhead of thread oversubscription. Also, an intense contention between the sender and the receivers makes things worse. VTune analysis confirms that this issue accounts for most of the CPU time (approximately 99%) and that effective CPU utilization is really poor:
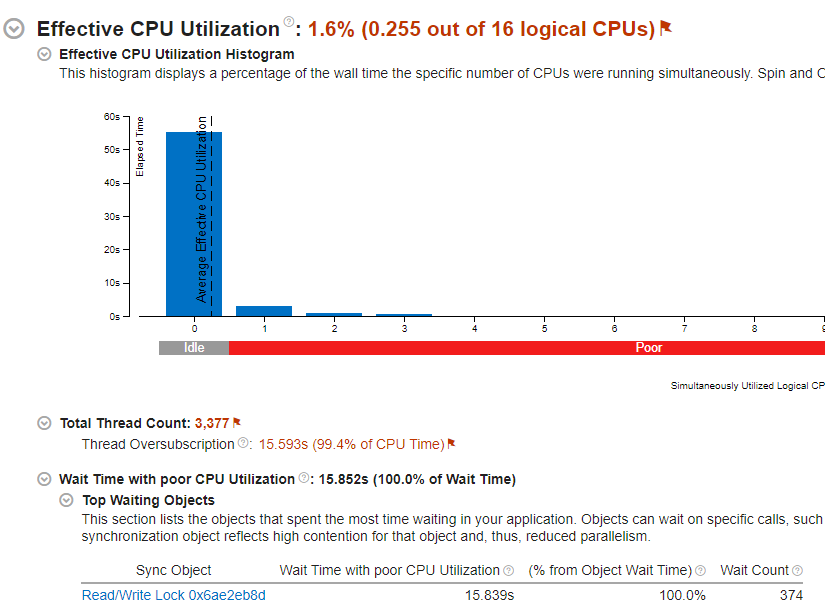
Now we add a little sleep to agent’s handler to simulate some non-CPU work:
void so_define_agent() override
{
so_subscribe(m_input).event([this](unsigned msg) {
if (--m_message_count == 0)
{
so_5::send<unsigned>(m_output, m_worker_id);
}
std::this_thread::sleep_for(5ms);
});
}
We set 100 workers and 100 messages, and we run the test again:
-
active_obj: total=0.5994843s (send=0.0011838s) -
thread_pool(size=4) individual fifo: 14.8028791s (send=0.00099s) -
active_group: total=58.0000189s (send=0.0010645s) -
thread_pool(size=4) cooperation fifo: 58.5062752s (send=0.0008479s)
In this scenario, maximizing the number of agents that sleep simultaneously seems to be the most effective strategy for reducing time. As a result, active_obj emerges as the winner, since it allows multiple agents to sleep concurrently. In contrast, active_group and thread pools with cooperation FIFO are unable to set sleeping threads. A thread pool with individual FIFOs can roughly allow four threads to sleep simultaneously, thereby reducing the total time approximately by a factor of four. In this case, max_demands_at_once does not influence the results.
The last test consists in making agents use the CPU a bit. A simple way to achieve this consists in calling a mathematical computation such as std::sph_neumann(). The function is very fast but we hope the CPU usage will be higher when invoked in parallel:
class performer final : public so_5::agent_t
{
public:
// ... as before
void so_define_agent() override
{
so_subscribe(m_input).event([this](unsigned msg) {
series += sph_neumann(msg, 1.2345);
if (--m_message_count == 0)
{
so_5::send<unsigned>(m_output, m_worker_id);
}
});
}
private:
// ... as before
double series = 0.0;
};
First of all, we time only sending with message_count=100’000 and workers_count=10:
-
active_group: send=0.0856722s -
thread_pool(size=4) cooperation fifo: send=0.0863497s -
thread_pool(size=4) individual fifo: send=0.1026605s -
active_obj: send=0.1215744s
Setting workers_count to 100 influences significantly only active_obj:
-
active_group: send=0.9371961s -
thread_pool(size=4) cooperation fifo: send=0.9761272s -
thread_pool (size=4) individual fifo: send=1.0853132s -
active_obj: send=8.5098566s
Essentially, the performance of so_5::send is influenced by both the number of subscribers and the type of dispatcher they are bound to. The dispatcher determines the number of event queues the sender must push events to, as well as the number of threads that will compete for such queues.
In the case of 100 workers, both active_group and the thread pools maintain the same number of threads as the previous case with 10 workers. Thread pool with individual FIFO creates one queue per agent but the contention is still with 4 threads. On the other hand, active_obj spawns a thread and a queue per agent, resulting in a much more significant queue contention than before.
Indeed, it’s important to consider that senders can be influenced by factors beyond their control, such as the number of subscribers (and their dispatchers) to the channels they send data to, as well as message limits, filters and message chains overflow strategies we discussed in previous posts.
Now, we launch the benchmark with these parameters – still a relatively small number of agents:
-
workers_count=100 -
message_count=10’000
The results follow:
-
active_obj: 1.4000212s (send=0.5400204s) -
thread_pool(size=16) individual fifo: 1.5410626s (send=0.3494862s) -
thread_pool(size=4) individual fifo: 3.018587s (send=0.1105012s) -
active_group: 10.8314913s (send=0.0921994s) -
thread_pool(size=4) cooperation fifo: 11.1894452s (send=0.1094321s)
In this case, active_obj is still the winner, as the operation is highly parallelizable, and the number of workers is contained. Allocating one dedicated thread per agent is managed well by the operating system despite the oversubscription (clearly, the CPU usage is quite intense, with peaks of ~80% usage overall, consuming ~700MB of memory).
On the other hand, active_group does not parallelize at all, likewise thread pools without cooperation FIFO. On the other hand, a thread pool with 16 threads and individual FIFO shows performance comparable to active_obj but resulting in less oversubscription.
Another interesting variation of this setup consists in configuring a high number of workers (10’000) but a small number of messages (100) and see the differences between individual thread pools and active_obj:
-
thread_pool(size=4, max_demands_at_once=1) individual fifo: 1.3885312s (send=1.3247622s) -
thread_pool(size=4, max_demands_at_once=4) individual fifo: 1.9491221s (send=1.8848592s) -
active_obj: 5.4890432s (send=3.2413613s)
As expected, active_obj is a suboptimal choice as the number of workers is too high.
These considerations highlight that we should take active_obj with a grain of salt. Ideally, dedicating one thread per agent is the simplest design choice but it might have important performance implications, as we have just seen.
Observing the bulk effect
The final benchmark we’ll briefly discuss in this article is a variation of the previous one: instead of data being produced by a centralized producer, we have agents that send messages to themselves until a certain number of messages is processed. Once completed, they send a notification to the “master” agent. Each worker sends several messages to itself right after the start and this parameter will be configurable. Thus, the agents work independently from each other:
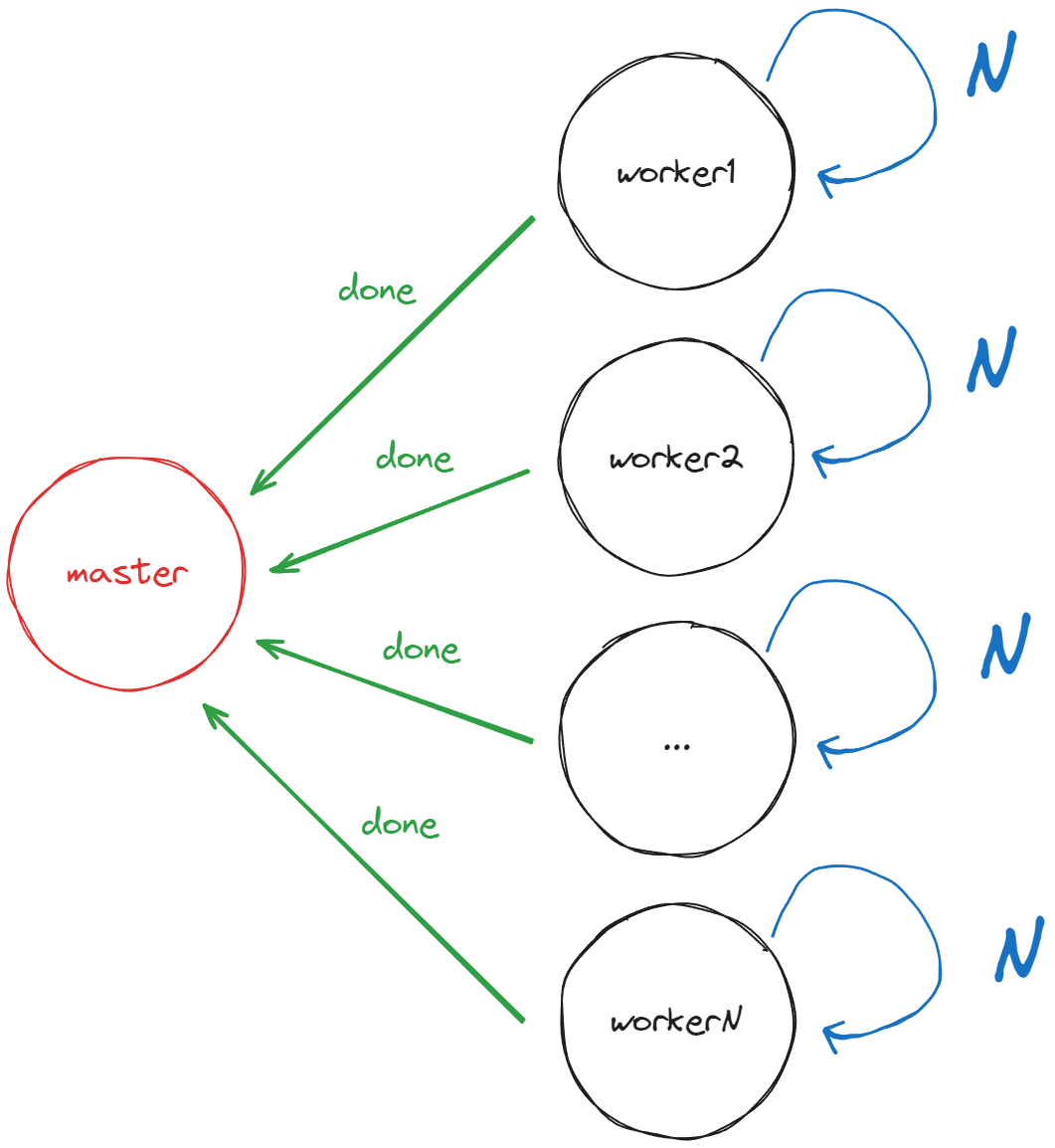
The purpose is to highlight the overhead on the service of a large number of queues on dispatchers with thread pools. Differently from the previous scenario, in this case the contention on the same queue is insignificant.
The code is here below:
template<unsigned workers_count>
class master final : public so_5::agent_t
{
public:
master(so_5::agent_context_t c)
: agent_t(std::move(c))
{
}
void so_define_agent() override
{
so_subscribe_self().event([this](unsigned worker_id) {
m_done_received[worker_id] = true;
if (m_done_received.all())
{
so_environment().stop();
}
});
}
private:
std::bitset<workers_count> m_done_received;
};
class worker : public so_5::agent_t
{
struct self_signal final : so_5::signal_t {};
public:
worker(so_5::agent_context_t c, unsigned message_count, unsigned start_batch, unsigned worker_id, so_5::mbox_t dest)
: agent_t(std::move(c)), m_message_count(message_count), m_start_batch(std::max(1u, start_batch)), m_worker_id(worker_id), m_output(std::move(dest))
{
}
void so_evt_start() override
{
for (auto i=0u; i<m_start_batch; ++i)
{
so_5::send<self_signal>(*this);
}
}
void so_define_agent() override
{
so_subscribe_self().event([this](so_5::mhood_t<self_signal>) {
if (--m_message_count != 0)
{
so_5::send<self_signal>(*this);
}
else
{
so_5::send<unsigned>(m_output, m_worker_id);
}
});
}
private:
unsigned m_message_count;
unsigned m_start_batch;
unsigned m_worker_id;
so_5::mbox_t m_output;
};
TEST(benchmarks, self_send)
{
constexpr auto workers_count = 50;
constexpr auto message_count = 1000000;
constexpr auto start_batch = 1;
const auto tic = std::chrono::steady_clock::now();
so_5::launch([](so_5::environment_t& env) {
env.introduce_coop([&](so_5::coop_t& coop) {
const auto master_mbox = coop.make_agent<master<workers_count>>()->so_direct_mbox();
const auto thread_pool = make_dispatcher(env, "workers",
so_5::disp::thread_pool::disp_params_t{}
.thread_count(16))
.binder(so_5::disp::thread_pool::bind_params_t{}.
fifo(so_5::disp::thread_pool::fifo_t::individual)
.max_demands_at_once(1)
);
for (auto i = 0u; i < workers_count; ++i)
{
coop.make_agent_with_binder<worker>(thread_pool, message_count, start_batch, i, master_mbox);
}
});
});
const auto elapsed = std::chrono::duration<double>(std::chrono::steady_clock::now() - tic).count();
std::cout << std::format("self-send (message_count={} worker_count={}) elapsed={}\n", message_count, workers_count, elapsed);
}
The interesting part of this benchmark is the effect of varying max_demands_at_once to observe the so-called bulk effect (or batch effect). In essence, in presence of a dense flow of events, a thread that processes more messages from a queue instead of frequently switching to other queues might improve performance. Indeed, with these parameters:
-
workers_count=50 -
message_count=1M -
start_batch=1
The test shows different values of elapsed time depending on max_demands_at_once:
- 16 threads and
max_demands_at_once=100 takes 0.9673126s - 4 threads and
max_demands_at_once=100 takes 1.6485941s - 4 threads and
max_demands_at_once=4 takes 3.2874836s - 16 threads and
max_demands_at_once=4 takes 4.3633599s - 4 threads and
max_demands_at_once=1 takes 9.8537081s - 16 threads and
max_demands_at_once=1 takes 16.267653s
max_demands_at_once=4 is mentioned because it’s the default value. The interpretation of these numbers is clear: when threads minimize switching while processing “hot” queues, the overall performance improves.
When increasing the number of workers and the start batch:
-
workers_count=1’000 -
message_count=1M -
start_batch=100
The bulk effect is consistent:
- 16 threads and
max_demands_at_once=50’000 takes 16.383999s - 16 threads and
max_demands_at_once=10’000 takes 16.48325301s - 16 threads and
max_demands_at_once=1’000 takes 17.2395806s - 16 threads and
max_demands_at_once=100’000 takes 17.7065044s - 16 threads and
max_demands_at_once=100 takes 19.4542036s - 16 threads and
max_demands_at_once=4 takes 80.6875612s - 16 threads and
max_demands_at_once=1 takes 81.2743937s
For this specific setup, the optimal value for max_demands_at_once is around 50,000, while 100,000 performs slightly worse than 1,000. The worst performer is 1, as the CPU constantly switches threads from one queue to another. Considering that each handler enqueues a new event into the same queue, the processing thread is guaranteed to find at least max_demands_at_once events to process. However, the drawback is the risk of starvation: once an agent is selected for processing, it monopolizes the worker thread for max_demands_at_once events.
Thus, max_demands_at_once is an important setting that might give very different performance results when dealing with a dense flow of events.
Final remarks
Exploring performance indicators and conducting typical benchmarks provides valuable insights into the costs and optimization options within SObjectizer and other actor frameworks. Through these investigations, we’ve gained a deeper awareness of various factors that influence system performance, including message passing overhead, agent management costs, and the impact of different dispatcher configurations. Armed with this knowledge, we can fine-tune applications to achieve optimal performance while meeting their specific requirements and constraints.
Numerous other benchmarks and performance tests remain unexplored, but now you should possess more tools to gain further insights into the topic. For instance, you could investigate the performance of message chains or compare the efficiency of using adv_thread_pool versus manually distributing work across multiple agents.
Our exploration of performance considerations is not yet complete. In a forthcoming post, we will continue this journey by examining additional components provided by SObjectizer that enable us to gather additional metrics and indicators while the application is running.
Takeaway
In this episode we have learned:
- typical actor framework benchmarks include agent management (creation and destruction), 1:1 and 1:N messaging, and impact of using multiple thread configurations;
- agent management has been evaluated through skynet, assessing the performance of agent creation and destruction. While managing thousands of agents is typically insignificant, creating and destroying one million agents might be something to avoid;
- 1:1 messaging has been benchmarked using ping-pong, a typical test measuring message exchange between two agents;
- 1:N messaging has been demonstrated by one producer and multiple consumers subscribed to the same channel, akin to
calico‘s scenario; - we demonstrated that using
active_objdispatcher is a suboptimal choice when the number of agents is too high; - we observed the performance of sending data is influenced by factors beyond its control such as the number of receivers and the dispatchers in use;
- we also observed the bulk (batch) effect in a variation of the above-mentioned benchmark;
-
so_5::launchis a self-contained function to instantiate, launch and keep alive a SObjectizer environment until explicitly stopped; -
thread_pooldispatcher’smax_demands_at_oncesetting determines how many events from a queue the thread has to process before switching to another queue; - in case of dense event flow, incresing
max_demands_at_oncemight result in better performance as the bulk effect is effectively handled.
As usual, calico is updated and tagged. In this regard, we have two considerations: first of all, the actual implementation of benchmarks in calico is slightly more “generalized” than that presented in this post as here we favored simplicity for the sake of explanation. Secondly, since come benchmarks take a while, you will find them all disabled. To run calico_tests executing benchmarks, add the command line option:
--gtest_also_run_disabled_tests
For example:
calico_tests.exe --gtest_also_run_disabled_tests
By the way, please consider these benchmarks do not pertain to calico but are added in its suite for simplicity and to let you play with them without the bother of creating a new project.
What’s next?
As our discussion with Helen regarding performance comes to a close, she remains interested in understanding how service_time_estimator_dispatcher can avoid copying execution_demand_t instances while making modifications during processing. Is this a general feature or an isolated case?
In the upcoming post, we’ll learn a new feature of SObjectizer pertaining to 1:1 messaging that allows us to exchange “mutable” messages.
Thanks to Yauheni Akhotnikau for having reviewed this post.





Top comments (0)