
The Problem
The task revolves around the Person table that is structured as follows:
| id (PK) | |
|---|---|
| int | varchar |
Each row of this table contains an id (primary key) and an email. All emails are lowercase. We are asked to delete duplicate emails while preserving the one with the smallest id.
Explanation
Let's consider this scenario:
Input:
Person table:
| id | |
|---|---|
| 1 | john@example.com |
| 2 | bob@example.com |
| 3 | john@example.com |
Output:
| id | |
|---|---|
| 1 | john@example.com |
| 2 | bob@example.com |
Here, john@example.com was duplicated. We kept the row with the smallest id = 1.
The Solution
We'll explore three SQL solutions that handle this problem differently, discussing their main differences, strengths, weaknesses, and the structures.
Source Code 1
The first solution uses the ROW_NUMBER() function to assign a unique row number for each email group (partitioned by email). It then deletes the rows where the row number is greater than 1, thus keeping only the first entry of each email.
WITH rn_persons AS (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY email ORDER BY id) AS rn
FROM Person
)
DELETE
FROM rn_persons
WHERE
rn > 1
The runtime for this solution is 625ms, which beats 96.69% of other submissions.

Source Code 2
The second solution follows a similar approach to the first one, but it includes a subquery in the DELETE clause to target only the rows where the row number is greater than 1.
WITH cte AS (
SELECT
id,
ROW_NUMBER() OVER (PARTITION BY email ORDER BY id) AS rn
FROM Person
)
DELETE FROM Person
WHERE id IN (
SELECT id FROM cte WHERE rn > 1
)
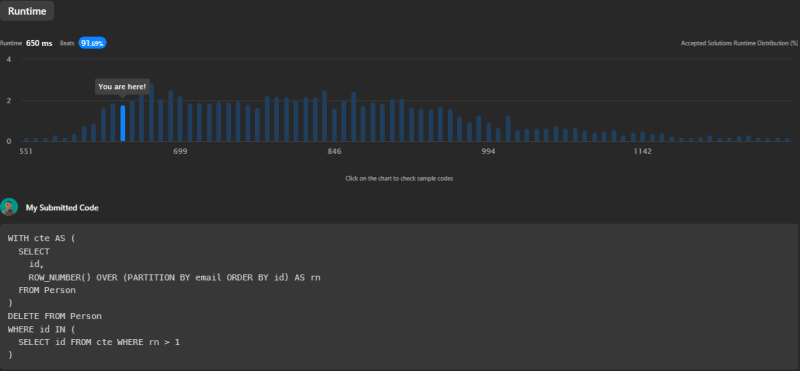
The runtime for this solution is 650ms, which beats 91.69% of other submissions.
Source Code 3
The third solution uses a JOIN operation to identify duplicate emails. If the id of the first table (p1) is larger than the id of the second table (p2), the row from the first table is deleted.
DELETE p1
FROM Person p1
JOIN Person p2 ON p1.email = p2.email
WHERE p1.id > p2.id
The runtime for this solution is 685ms, which beats 82.78% of other submissions.

Conclusion
All three solutions successfully delete duplicate emails from the Person table while keeping the email with the smallest id. However, their performances vary.
Ranking by performance, from best to worst, the solutions are: Source Code 1 > Source Code 2 > Source Code 3. This ranking may help you decide which approach to take, depending on your specific performance needs.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.





Top comments (1)
In Postgres you can do: