
The Problem
We have an Employee and a Department table in a database. The Employee table contains an id as the primary key, name, salary, and departmentId which is a foreign key from the Department table. The Department table contains an id as the primary key and name.
Our task is to write an SQL query to find the employees who earn the highest salary in each of their departments. We should return the result in any order.
Employee Table
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
Department Table
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
Input
Here's an example of the kind of input we can expect. Let's consider these records in the Employee and Department tables:
Employee
| id | name | salary | departmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Jim | 90000 | 1 |
| 3 | Henry | 80000 | 2 |
| 4 | Sam | 60000 | 2 |
| 5 | Max | 90000 | 1 |
Department
| id | name |
|---|---|
| 1 | IT |
| 2 | Sales |
Output
The output should list the highest earning employee(s) in each department along with their salaries. So, in this example, the output would be:
| Department | Employee | Salary |
|---|---|---|
| IT | Jim | 90000 |
| Sales | Henry | 80000 |
| IT | Max | 90000 |
The Solution
We are going to explore four different solutions, each using different SQL features and methodologies. These approaches will provide different insights into how to approach similar problems and will demonstrate the versatility and power of SQL.
Source Code 1: Using DENSE_RANK() window function
In the first approach, we use the DENSE_RANK() window function to rank salaries within each department. We then filter for employees who have a rank of 1 (highest salary) in their respective departments.
WITH ranking AS (
SELECT
d.name [Department],
e.name [Employee],
e.salary [Salary],
DENSE_RANK() OVER (PARTITION BY e.departmentId ORDER BY e.salary DESC) [drank]
FROM
Employee e JOIN Department d ON e.departmentId = d.id
)
SELECT
Department,
Employee,
Salary
FROM ranking
WHERE drank = 1
This solution's runtime is 703ms, which beats 69.86% of all other submissions on LeetCode.

Source Code 2: Using RANK() window function
This approach is similar to the first one, but instead of DENSE_RANK(), we use the RANK() window function. The difference between RANK() and DENSE_RANK() is that RANK() will create gaps in rank values when there are ties, whereas DENSE_RANK() will not.
WITH ranking AS (
SELECT
d.name [Department],
e.name [Employee],
e.salary [Salary],
RANK() OVER (PARTITION BY e.departmentId ORDER BY e.salary DESC) [rank]
FROM
Employee e JOIN Department d ON e.departmentId = d.id
)
SELECT
Department,
Employee,
Salary
FROM ranking
WHERE rank = 1
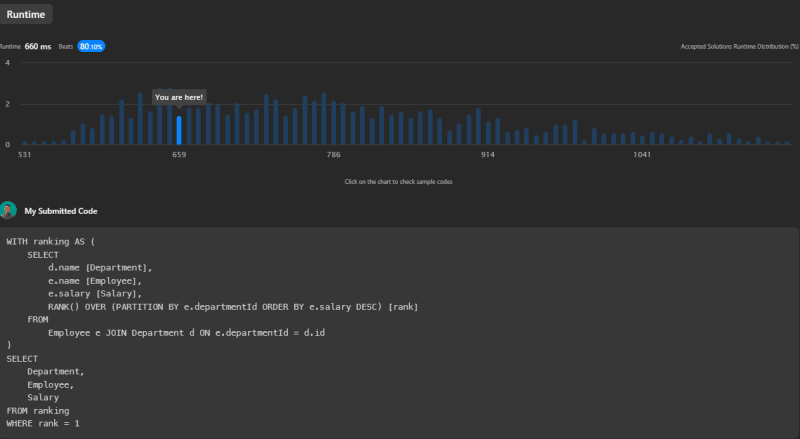
This solution's runtime is 660ms, which beats 80.10% of all other submissions on LeetCode.
Source Code 3: Using MAX() window function
This approach uses the MAX() window function to determine the maximum salary within each department. It then filters for employees whose salary is equal to the maximum salary in their respective departments.
WITH ranking AS (
SELECT
d.name [Department],
e.name [Employee],
e.salary [Salary],
MAX(e.salary) OVER (PARTITION BY e.departmentId) [max_per_dept]
FROM
Employee e JOIN Department d ON e.departmentId = d.id
)
SELECT
Department,
Employee,
Salary
FROM ranking
WHERE Salary = max_per_dept
This solution's runtime is 696ms, which beats 71.19% of all other submissions on LeetCode.

Source Code 4: Using GROUP BY and JOIN
In the final approach, we first determine the maximum salary within each department using a GROUP BY statement. We then join this result with the Employee and Department tables to retrieve the respective employees' names and their department names.
WITH max_salary AS (
SELECT
departmentId,
MAX(salary) [max_per_dept]
FROM Employee
GROUP BY departmentId
)
SELECT
d.name [Department],
e.name [Employee],
e.salary [Salary]
FROM
Employee e JOIN Department d ON e.departmentId = d.id
JOIN max_salary m ON m.departmentId = e.departmentId AND m.max_per_dept = e.salary
This solution's runtime is 908ms, which beats 24.39% of all other submissions on LeetCode.

Conclusion
Each of the four approaches used different SQL features to solve the problem. Some used window functions, others used the traditional GROUP BY statement, while others combined both.
In terms of performance on LeetCode:
- The second approach with the
RANK()function was the most performant (660ms runtime, beats 80.10%). - The first approach with
DENSE_RANK()came second (703ms runtime, beats 69.86%). - The third approach with
MAX()came third (696ms runtime, beats 71.19%). - The fourth approach with
GROUP BYandJOINwas the least performant (908ms runtime, beats 24.39%).
However, it's essential to note that these rankings might vary based on the actual real-world relational database management system (RDBMS) and data distribution.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.





Top comments (0)