
The Problem
You're given a table Activities with columns sell_date (of type date) and product (of type varchar). The table doesn't have a primary key, so it may contain duplicate entries. Each row of this table contains the product name and the date it was sold in a market.
| Column Name | Type |
|---|---|
| sell_date | date |
| product | varchar |
The goal is to create an SQL query to identify, for each date, the number of different products sold and their names. The product names for each date should be sorted lexicographically. The output should be ordered by sell_date.
Explanation
| sell_date | product |
|---|---|
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
| 2020-06-02 | Mask |
| 2020-05-30 | T-Shirt |
The desired output from the above Activities table would be as follows:
| sell_date | num_sold | products |
|---|---|---|
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
The Solution
We will discuss two MSSQL solutions here, each using STRING_AGG for string concatenation and GROUP BY for aggregation, but with different strategies for eliminating duplicate products.
Source Code 1
In this approach, we perform string aggregation and product counting in the outer query, and in the inner query, we perform duplicate elimination:
SELECT
a.sell_date,
COUNT(DISTINCT a.product) [num_sold],
(
SELECT STRING_AGG(p.product, ',') WITHIN GROUP (ORDER BY p.product)
FROM (
SELECT DISTINCT product
FROM Activities
WHERE sell_date = a.sell_date
) p
) [products]
FROM Activities a
GROUP BY sell_date
ORDER BY sell_date
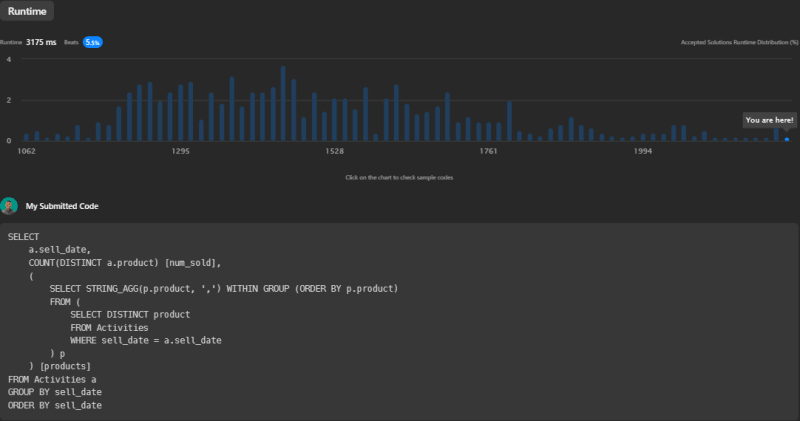
This query finishes in 3175ms, beating 5.5% of submissions.
Source Code 2
This solution differs by eliminating duplicates in a subquery before performing string aggregation and product counting:
SELECT
a.sell_date,
COUNT(DISTINCT a.product) [num_sold],
STRING_AGG(a.product, ',') WITHIN GROUP (ORDER BY a.product) [products]
FROM (
SELECT DISTINCT
sell_date,
product
FROM Activities
) a
GROUP BY a.sell_date
ORDER BY a.sell_date
This query finishes in 1635ms, beating 32.40% of submissions.

Conclusion
These solutions highlight the importance of choosing the right approach when dealing with data manipulation. The second solution is more efficient, primarily because it eliminates duplicates early on in a subquery.
Please note that although these solutions' performance was measured on LeetCode, the actual performance may vary based on the specific RDMS, the database structure, and the size of the data.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.





Top comments (1)
for second approach do we need DISTINCT inside COUNT because a is already doing DISTINCT.
I am talking about line
COUNT(DISTINCT a.product) [num_sold],